

 Login
Login

 January 20, 2026
January 20, 2026|
Voiced by Amazon Polly |
Introduction
Data lineage is often discussed as a governance or metadata problem, but in modern data engineering platforms, it is fundamentally an execution problem. Most production data systems running on Amazon Web Services rely heavily on custom code, Python scripts, Spark jobs, SQL embedded in orchestration logic, and Lambda-based transformations. In such environments, lineage that is inferred after the fact from tables, catalogs, or query history is incomplete by design.
The primary reason is simple, the most accurate description of data movement exists only at runtime. Conditional logic, dynamically generated paths, schema evolution, retries, and partial failures all occur during execution and are invisible to static metadata scanners. As a result, lineage systems that rely solely on downstream observation fail precisely when engineers need them most, during incidents, audits, and root-cause analysis.
This document focuses on the first and most critical layer of a production-grade lineage platform: script-centric lineage capture using structured logging on AWS. The core idea is to treat logging not as an observability afterthought, but as a first-class lineage signal that is emitted directly by data pipelines at execution time. This approach establishes deterministic, replayable, and auditable lineage without introducing non-AWS dependencies or black-box tools.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Problem Context: Why Traditional Lineage Approaches Fail
Before detailing the solution, it is important to understand the systemic limitations of common lineage strategies.
- Warehouse-Driven Lineage Is Inherently Incomplete
Lineage derived from analytical engines (e.g., query history or system tables) captures only what happens within those engines. Any upstream processing, file ingestion, schema normalization, enrichment, or deduplication remains opaque. On AWS-based platforms, this upstream work often accounts for the majority of the business logic.
- Static Code Analysis Alone Cannot Represent Reality
Static parsing of scripts can identify potential sources and targets, but it cannot answer questions such as:
- Which branch of conditional logic was executed?
- Which dynamic path was resolved at runtime?
- Did a partial write occur before a failure?
- Which schema version was actually used?
Static analysis describes possibility, not truth.
- Lineage Reconstruction After Incidents Is Too Late
In operational scenarios, engineers need lineage during or immediately after execution. Reconstructing lineage days later from partial metadata significantly increases mean-time-to-resolution and introduces human error.
These constraints motivate a shift toward execution-time lineage capture, where pipelines explicitly declare their data interactions as they occur.
Design Overview: Script-Centric Lineage on AWS
The proposed design introduces a dedicated lineage capture plane that operates alongside data processing workloads. This plane is implemented entirely using AWS-native services and integrates directly with existing pipelines.
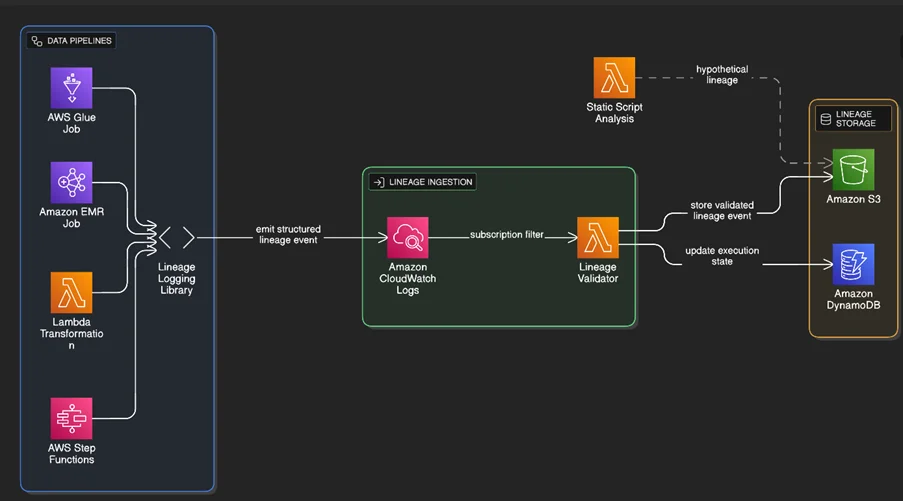
Core AWS Services Used
- AWS Glue and Amazon EMR for batch and Spark-based ETL
- AWS Lambda for lightweight transformations and ingestion
- AWS Step Functions for orchestration and execution context
- Amazon CloudWatch Logs for centralized log ingestion
- AWS Lambda (lineage validator) for schema enforcement
- Amazon S3 for immutable lineage event storage
- Amazon DynamoDB for active execution state tracking
No external agents, databases, or SaaS lineage tools are required.
Logging as a Deterministic Lineage Contract
Why Logs Are the Most Reliable Lineage Signal
Unlike metadata crawlers or query logs, application logs are emitted by the code that performs the transformation. This makes them uniquely suited to express intent, context, and execution outcomes. When structured correctly, logs can encode lineage with precision that no downstream inference can match.
However, this is only true if logs are designed, not improvised.
The Mandatory Lineage Log Schema
Every pipeline step that reads or writes data must emit a lineage event conforming to a versioned JSON schema. At a minimum, each event captures:
- Pipeline identifier
- Execution (run) identifier
- Step name
- Source system and location
- Target system and object
- Operation type (read, write, transform)
- Schema or version identifier
- Record-level metrics when available
An example lineage event emitted from an AWS Glue job:
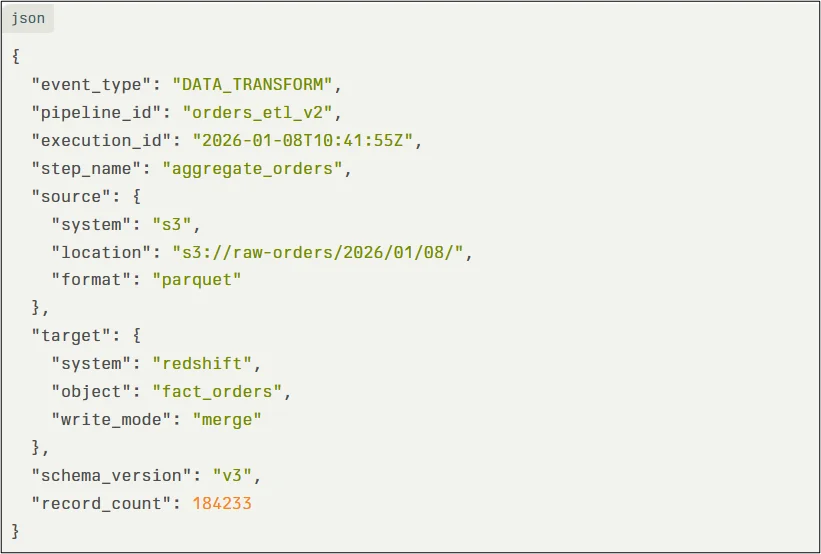
This schema is intentionally explicit. Ambiguity is the enemy of lineage.
Enforcing Lineage Logging at Runtime
Shared Lineage Logging Library
To ensure consistency, all pipelines use a shared lineage logging library distributed as:
- A Python wheel for AWS Glue
- An Amazon EMR bootstrap artifact
- AWS Lambda Layer for serverless pipelines
This library performs three critical functions:
- Injects execution context (pipeline ID, run ID, orchestration metadata)
- Validates lineage events against the approved schema
- Ensures logs are flushed even during unhandled exceptions
Failing Fast on Missing Lineage
A key design decision is that lineage emission is not optional. If a pipeline step cannot emit a valid lineage event, the job fails. This prevents silent lineage gaps, which are far more damaging than visible pipeline failures.
Lineage Ingestion and Validation Flow on AWS
Once emitted, lineage events flow through a dedicated ingestion pipeline:
- Emission
Lineage events are written to standard output by AWS Glue, Amazon EMR, or AWS Lambda. - Centralization
Amazon CloudWatch Logs captures all events in a centralized log group. - Validation
Amazon CloudWatch Logs subscription filter forwards events to an AWS Lambda validator, which:- Validates schema versions
- Enriches events with ingestion timestamps
- Rejects malformed or incomplete events
- Persistence
- Amazon S3 stores validated events in an append-only, partitioned layout
- Amazon DynamoDB tracks active executions and step-level state
The Amazon S3 archive acts as the immutable system of record, enabling replay, reprocessing, and audit reconstruction.
Complementary Static Script Analysis
While runtime logging provides execution truth, static analysis still plays a role. AWS Lambda periodically scans scripts stored in Amazon S3 or AWS CodeCommit functions to extract potential lineage paths. These paths are explicitly tagged as non-executed and are used later for comparison, validation, and coverage analysis.
This separation ensures that hypothetical lineage never pollutes execution-grade lineage.
Failure Scenarios and System Behavior
The lineage capture system is explicitly designed to degrade safely:
- Pipeline crash mid-step
Partial lineage is preserved and marked incomplete. - Job retries
Each retry generates a new execution node, maintaining historical accuracy. - Schema drift
New schema versions are recorded without overwriting prior lineage. - Validator failure
Events are rejected and surfaced immediately, preventing silent corruption.
At no point is lineage inferred or guessed when signals are missing.
Conclusion
Script-centric lineage capture is the foundation of any serious data lineage platform. By embedding lineage emission directly into pipeline code and enforcing it through structured logging, AWS-native services can deliver deterministic, auditable lineage without external tooling.
Subsequent layers, graph modeling, GenAI enrichment, and operational analytics are only viable because this execution-grade lineage foundation exists.
Check out for Part 2 and Part 3 here.
Drop a query if you have any questions regarding Script-centric lineage and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Why not rely only on AWS Glue Data Catalog for lineage?
ANS: – The AWS Glue Data Catalog captures schema and table metadata but does not represent execution-time behavior, conditional logic, or partial failures.
2. Does structured logging add runtime overhead?
ANS: – The overhead is minimal compared to ETL processing costs and is offset by significant gains in debuggability and auditability.
3. Can this approach work for both batch and streaming pipelines?
ANS: – Yes. The same logging contract applies to AWS Glue jobs, Amazon EMR Spark streaming jobs, and AWS Lambda-based near-real-time pipelines.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments