

 Login
Login
 December 2, 2025
December 2, 2025|
Voiced by Amazon Polly |
Overview
Amazon Bedrock now empowers users with custom model on-demand deployment, a capability that allows organizations to deploy and run their fine-tuned or customized foundation models only when needed. This feature enables users to control inference costs, scale efficiently, and optimize performance for specific workloads, all while leveraging the secure and managed infrastructure of AWS.
Traditionally, deploying foundation models required maintaining them in a provisioned throughput setup, leading to continuous costs even during idle periods. The on-demand model deployment capability solves this challenge by enabling pay-per-use inference, making it an ideal solution for variable workloads, experimentation, and cost-optimized AI applications.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
In today’s fast-evolving AI ecosystem, enterprises are increasingly demanding flexibility in how they utilize large language models (LLMs) and other foundational models. While custom models fine-tuned on proprietary data deliver accuracy and domain relevance, managing their deployment efficiently has often been a challenge, especially for organizations with fluctuating workloads.
In simpler terms, you create a custom model, deploy it with on-demand settings, and pay only for what you use. The service automatically handles infrastructure provisioning and scaling, freeing data scientists and developers to focus on model innovation rather than operational overhead.
How It Works?
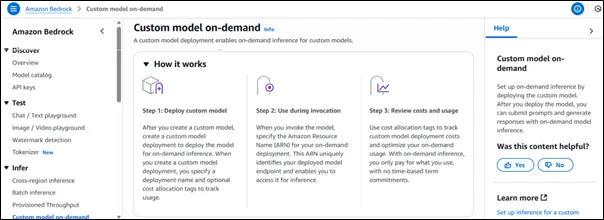
Amazon Bedrock simplifies the process of using on-demand model inference through three straightforward steps:
Step 1: Deploy Custom Model
After creating or fine-tuning a custom model in Amazon Bedrock, you can deploy it using the Custom Model On-Demand option. During deployment, you provide a unique deployment name and optionally apply cost allocation tags to track expenses.
This deployment establishes the infrastructure necessary for on-demand inference, meaning you don’t need to keep the model running continuously. It automatically scales up when invoked and scales down when inactive.
Step 2: Use During Invocation
Once the model is deployed, you can start invoking it through APIs by specifying its Amazon Resource Name (ARN). The ARN uniquely identifies your deployment and acts as a secure endpoint for inference requests.
This approach enables developers to integrate the model seamlessly into their applications. Whether you’re generating summaries, performing text classification, or running image analysis, the inference is executed only when a request is made, ensuring resource efficiency and cost control.
Step 3: Review Costs and Usage
Amazon Bedrock provides cost allocation tags that help track and analyze spending on each model deployment. Since the billing is purely usage-based, you only pay for the inference operations performed, without any time-based commitments.
The usage data can be integrated with AWS Cost Explorer and AWS Budgets, giving organizations clear visibility into how frequently their models are used and where optimization opportunities exist.
To get started with
Key Features of Custom Model On-Demand Deployment
- Pay-per-Use Model
You are billed only for the number of inference requests made, not for idle time. This reduces costs significantly for workloads that are intermittent or experimental. - Scalability and Elasticity
Amazon Bedrock automatically manages scaling, allowing the model to handle high inference volumes when needed and shut down gracefully during periods of low demand. - Seamless Integration with AWS Services
Models can be invoked through Amazon API Gateway, AWS Lambda, or custom applications running on Amazon EC2 or containers, enabling smooth integration within existing architectures. - Fine-Tuned Model Support
On-demand deployment supports custom models trained using Amazon Bedrock Customization (fine-tuning) workflows, ensuring domain relevance and optimized performance. - Operational Simplicity
No need to manage underlying infrastructure or manually scale servers, AWS takes care of provisioning and deprovisioning behind the scenes. - Secure Access Control
AWS IAM-based permissions ensure that only authorized users or applications can invoke specific model deployments, safeguarding intellectual property and data privacy.
Pros and Cons
Pros
Cost Efficiency:
Pay only for actual usage, avoiding idle infrastructure costs.
Flexibility:
Ideal for workloads with unpredictable traffic patterns or periodic demand.
Scalable and Managed:
AWS automatically handles scaling, fault tolerance, and maintenance.
Supports Multiple Models:
Organizations can maintain multiple on-demand deployments for various use cases without incurring significant infrastructure investment.
Simplified Experimentation:
Great for testing fine-tuned models before moving to a provisioned throughput setup.
Cons
Cold Start Latency:
Since the model is deployed dynamically, initial invocations may experience a brief delay before the model becomes active.
Limited Persistent Sessions:
On-demand models may not be ideal for applications requiring continuous, low-latency interactions.
Monitoring Complexity:
While cost allocation tags help track expenses, fine-grained monitoring may require additional AWS tooling, such as Amazon CloudWatch or AWS Cost Explorer configurations.
Conclusion
Amazon Bedrock’s Custom Model On-Demand Deployment marks a pivotal advancement in AI model management. By enabling users to deploy and invoke fine-tuned models only when needed, AWS delivers a perfect balance between cost efficiency and performance scalability.
For startups, research teams, and enterprises experimenting with multiple foundation models, this feature is a game-changer. It eliminates unnecessary operational costs and empowers teams to innovate at scale without overcommitting resources.
As AI adoption accelerates, flexibility and efficiency will become central to success, and Amazon Bedrock’s on-demand model deployment provides exactly that. Whether you’re running low-frequency inference tasks or building intelligent applications with fluctuating usage patterns, this capability ensures you pay less, perform better, and innovate faster.
Drop a query if you have any questions regarding Amazon Bedrock and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is the difference between on-demand deployment and provisioned throughput in Amazon Bedrock?
ANS: – Provisioned throughput reserves fixed capacity for continuous inference, leading to consistent performance but higher idle costs. In contrast, on-demand deployment activates only during inference requests and bills accordingly, making it ideal for unpredictable workloads.
2. Can I use on-demand deployment with fine-tuned models?
ANS: – Yes. On-demand deployment fully supports models fine-tuned using Bedrock’s customization workflow. Once the model is created, it can be deployed on demand and invoked using its ARN.
3. Is there any performance trade-off when using on-demand deployments?
ANS: – The main trade-off is cold start latency during initial invocations, as the model infrastructure is dynamically provisioned. However, subsequent invocations typically perform with minimal delay.

WRITTEN BY Yerraballi Suresh Kumar Reddy
Suresh is a highly skilled and results-driven Generative AI Engineer with over three years of experience and a proven track record in architecting, developing, and deploying end-to-end LLM-powered applications. His expertise covers the full project lifecycle, from foundational research and model fine-tuning to building scalable, production-grade RAG pipelines and enterprise-level GenAI platforms. Adept at leveraging state-of-the-art models, frameworks, and cloud technologies, Suresh specializes in creating innovative solutions to address complex business challenges.











Comments