

 Login
Login

 December 1, 2025
December 1, 2025|
Voiced by Amazon Polly |
In today’s data-driven world, organizations increasingly demand that data be shared across teams, partners and platforms without duplicating, exporting or breaking governance controls. Enter Delta Sharing, an open protocol from Databricks that aims to simplify secure, real-time data sharing across organizations and platforms.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
What Is Delta Sharing?
At its core, Delta Sharing is an open protocol developed by Databricks for safe, real-time sharing of tabular data across platforms and organizations without requiring data copying or data duplication. Because it’s open, it can work across cloud providers, on-premises systems and heterogeneous compute environments.
When used with Databricks, Delta Sharing becomes part of a secure data-sharing platform that lets you share not only tables, but also AI models, notebooks, views and volumes (under Unity Catalog) with external users.
A few characteristics to highlight:
- Zero-copy sharing: Recipients query the same underlying data files (e.g. in cloud object storage) rather than having to ingest a copy.
- Governance & auditing: Because shares are managed and controlled, one can track usage, enforce permissions and manage lifecycle centrally.
- Platform-agnostic: Delta Sharing supports clients such as Spark, Pandas, Tableau, Power BI and more.
Key Components of Delta Sharing
Delta Sharing is built around four key elements: shares, providers, recipients and the Delta Sharing server.
A share is a read-only collection of data assets, such as tables, views, notebooks, models and volumes, that a provider makes available to recipients. In Unity Catalog, it’s a securable object, and deleting it removes recipient access.
A provider is the entity that owns and shares data. Providers manage shares and recipients through a Unity Catalog–enabled Databricks workspace without needing to migrate existing ones.
A recipient is the entity that receives shared data. Defined as a securable object in Unity Catalog, a recipient uses credentials to access one or more shares. Removing a recipient from the metastore revokes all access.
The Delta Sharing Server (or Protocol Layer) handles authentication, access control and request coordination. In Databricks-to-Databricks sharing, these processes are built in, while open sharing for external users involves credential exchanges using tokens or OIDC.
The Underlying Storage holds the actual data in cloud object stores such as S3, ADLS or GCS, typically in Delta Lake or Parquet format. Recipients read directly from this storage while maintaining snapshot consistency and ACID guarantees.
Types of Data Sharing in Databricks
Delta Sharing supports two primary modes of data exchange:
Databricks-to-Databricks Sharing – Used when both the provider and recipient are on Unity Catalog–enabled Databricks workspaces. This method offers a seamless experience without the need for credential files, as access is managed directly through Unity Catalog.
Open Sharing – Designed for recipients outside Databricks. In this mode, data is shared securely using bearer-token credentials or OIDC federation, allowing external users and systems to access shared datasets while maintaining strict access control.
Databricks Delta Sharing Architecture
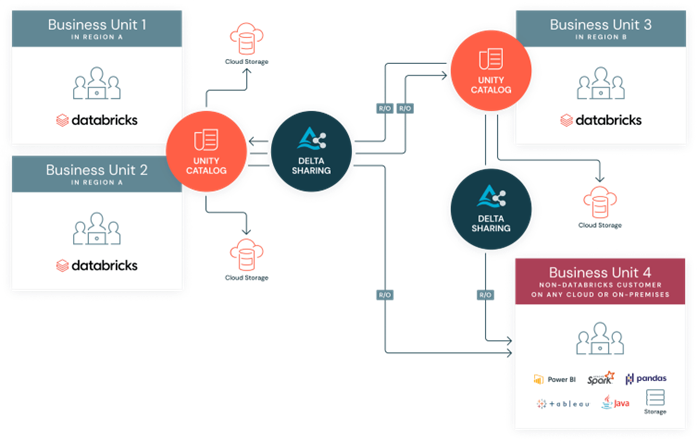 Source: Databricks Delta Sharing – Data Sharing
Source: Databricks Delta Sharing – Data Sharing
The above is an architectural diagram depicting the Databricks Delta Sharing workflow. It illustrates two provider business units (Business Unit 1 and Business Unit 2 in Region A), which manage their data through a centralized Unity Catalog and underlying Cloud Storage.
The flow shows the Delta Sharing protocol facilitating Read-Only (R/O) access to two main types of recipients:
- Databricks-to-Databricks Sharing: Business Unit 3 (in Region B), a Databricks customer, accesses the shared data using its own Unity Catalog.
- Open Sharing: Business Unit 4 (a non-Databricks customer on any cloud or on-premises) accesses the data using various client tools, including Power BI, Tableau, Spark, Pandas and Java.
The diagram highlights that the sharing is cross-region, cross-platform, and centrally governed via Unity Catalog.
Benefits and Use Cases of Delta Sharing
Databricks Delta Sharing enables secure, real-time data collaboration without data duplication. Its zero-copy architecture allows recipients to access live data directly from the provider’s storage, reducing cost and ensuring consistency. With centralized governance in Unity Catalog, organizations can easily manage permissions, audit usage and maintain compliance. The open protocol supports multiple platforms and tools like Spark, Pandas and Power BI, making cross-platform sharing simple and efficient.
Delta Sharing is ideal for securely exchanging data across teams, departments or external partners. It’s used for distributing analytical datasets, sharing curated data products and enabling joint projects without complex ETL pipelines. Organizations also use it for building data marketplaces and improving supply chain visibility. By breaking down data silos, Delta Sharing helps accelerate collaboration and data-driven innovation.
Why Delta Sharing Matters
Delta Sharing fills a critical gap in the enterprise data landscape. Traditional methods such as data dumps, ETL pipelines, database replication or APIs are often complex, slow, hard to govern and inflexible. Delta Sharing offers a modern alternative: secure, governed, live data sharing with zero-copy access across platforms.
With this, organizations can:
- Break down data silos
- Enable cross-team or cross-company collaboration
- Monetize curated data sets
- Maintain centralized compliance, access control and audit capabilities
If your organization is already using Databricks and Unity Catalog, adopting Delta Sharing is a powerful next step in building a more connected, collaborative data ecosystem.
Further Reading & Links
- Databricks’ official documentation on Delta Sharing – What is Delta Sharing?
- Databricks product page for Delta Sharing – Delta Sharing
- To learn more about Databricks data engineering training – Master Data Engineering with Databricks
Driving the Next Wave of Data Collaboration
Databricks Delta Sharing enables secure, governed and real-time data sharing across teams and organizations without duplication. Its zero-copy architecture and Unity Catalog governance ensure consistency, compliance and seamless cross-platform access. Supporting both Databricks-to-Databricks and open sharing, it simplifies collaboration, accelerates analytics and helps break down data silos, making it a powerful solution for modern data-driven organizations.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Pankaj Choudhary
Pankaj Choudhary is the Azure Data Vertical Head at CloudThat, specializing in Azure Data solutions. With 14 years of experience in data engineering, he has helped over 5,000 professionals upskill in technologies such as Azure, Databricks, Microsoft Fabric, and Big Data. Known for his ability to simplify complex concepts and deliver hands-on, practical learning, Pankaj brings deep technical expertise and industry insights into every training and solution engagement. He holds multiple certifications, including Databricks Certified Data Engineer Associate, Microsoft Certified: Azure Data Engineer Associate, and Apache Spark Developer. His work spans building scalable Lakehouse architectures, designing PySpark-based ETL pipelines, enabling real-time analytics, and implementing CI/CD pipelines with Azure DevOps. Pankaj’s passion for empowering teams and staying at the forefront of data innovation shapes his unique, outcome-driven approach to learning and development.











Comments