

 Login
Login

 October 30, 2025
October 30, 2025|
Voiced by Amazon Polly |
Introduction
Graph databases are transforming the way organizations store and analyze highly connected data. Yet, crafting Gremlin queries to retrieve meaningful insights often demands specialized expertise, creating a gap between technical and non-technical users. To bridge this gap, we explore how Amazon Bedrock models, including Amazon Nova Pro, can automatically translate natural language into Gremlin queries. This enables business analysts, data scientists, and other users to interact with graph data intuitively, without needing to master complex query syntax. Now, we will walk through the approach, compare techniques for query generation, and demonstrate how large language models (LLMs) can be utilized to evaluate the accuracy and relevance of the generated queries.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Solution overview
It requires a thorough understanding of graph architecture and domain-specific knowledge embedded in the graph database to convert plain language inquiries into Gremlin queries. We broke down our strategy into three main phases to accomplish this:
- Recognizing and drawing on graph knowledge
- Graph structure akin to text-to-SQL processing
- Creating and running queries in Gremlin
The following diagram illustrates this workflow:
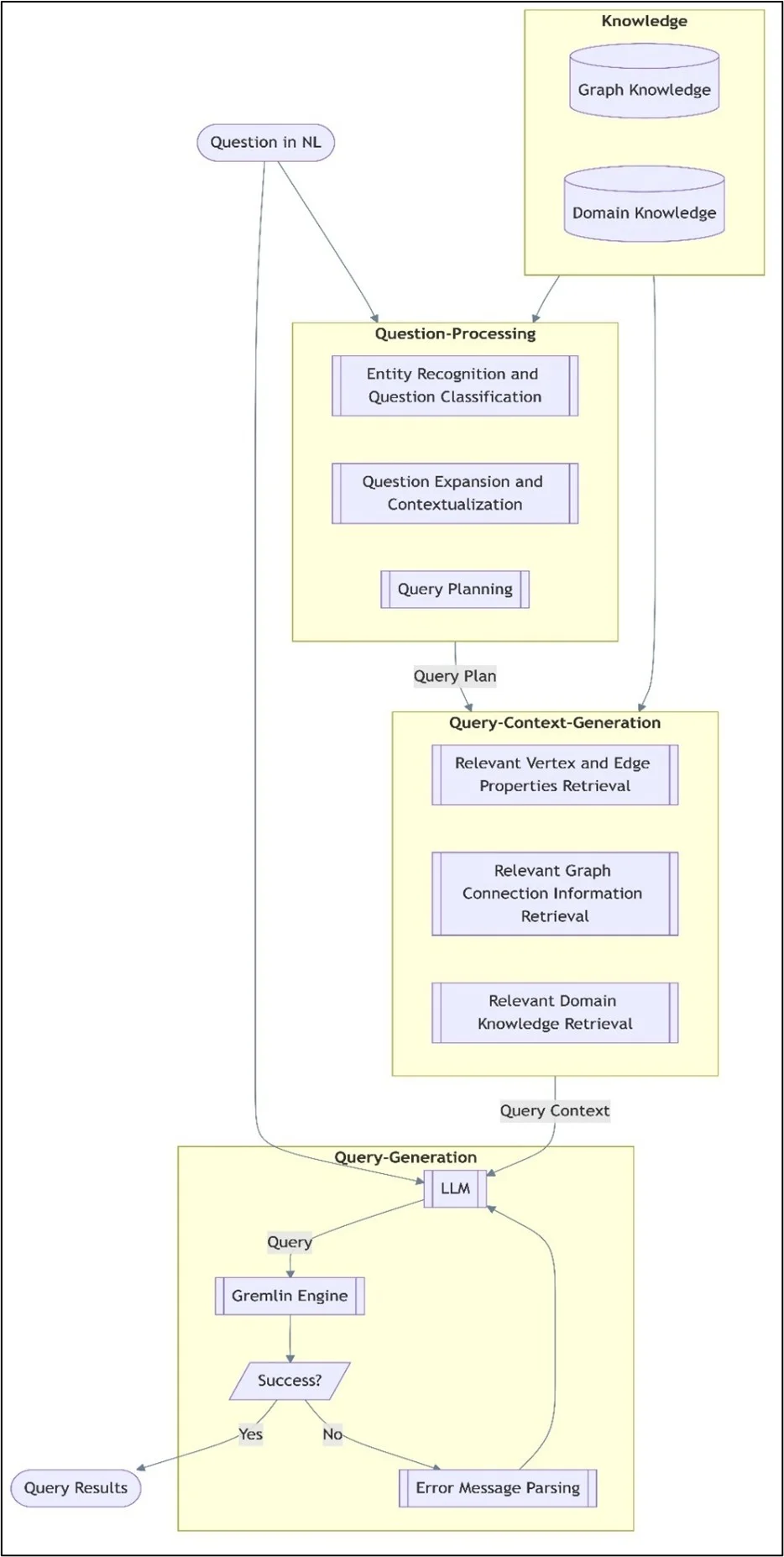
Step 1: Extract graph knowledge:
For a query generation framework to effectively interpret natural language inquiries, it must combine domain and graph knowledge. Semantic and structural data directly extracted from the graph database are referred to as graph knowledge. It consists of:
- Vertex kinds, names, and properties are listed in the vertex labels and properties section.
- Details on edge kinds and their characteristics are provided via edge labels and properties.
- Neighbors for each vertex that are one hop away. Recording local connectivity data, like the direct connections between vertices
The framework can efficiently reason about the intricate relationships and diverse attributes that are intrinsic to graph databases thanks to this graph-specific knowledge.
Additional context relevant to the application domain and complementary to graph information is captured through domain knowledge. There are two sources for it:
- Domain knowledge supplied by the client: For instance, the customer, kscope.ai, assisted in identifying the vertices that represent metadata and should never be searched. These embedded limitations guide the query generating process.
- LLM-generated summaries: We utilize an LLM to generate comprehensive semantic descriptions of vertex names, attributes, and edges, thereby enhancing the system’s comprehension of vertex labels and their relevance to queries. These explanations, stored in the domain knowledge repository, provide additional background information to make the generated questions more relevant.
Step 2: Graph structure akin to text-to-SQL processing:
Using a method akin to text-to-SQL processing, we build a schema that represents vertex types, edges, and characteristics to enhance the model’s understanding of graph topologies. This organized representation enhances the model’s ability to comprehend and generate insightful questions.
To generate queries, the question processing component converts natural language input into structured pieces. It functions in three phases:
- Key database components in the input question, such as vertices, edges, and characteristics, are identified by entity identification and classification, which then classifies the question according to its purpose.
- Context augmentation adds pertinent details from the knowledge component to the query, ensuring that the context is appropriately recorded for both graphs and domains.
- The improved question is mapped to certain database components required for query execution using query planning.
By putting together the following, the context generation component ensures that the resulting queries appropriately represent the underlying graph structure:
- Element properties: Returns the data types and characteristics of vertices and edges.
- Graph structure makes it easier to align with the topology of the database.
- Domain rules: Uses logic and business constraints
Step 3: Creating and running queries in Gremlin:
Query generation is the last stage, in which the LLM uses the extracted context to create a Gremlin query. The steps in the procedure are as follows:
- The LLM creates the first Gremlin query.
- A Gremlin engine is used to run the query.
- Results are delivered if the execution is successful.
- An error message parsing system examines the returned errors and uses LLM-based feedback to improve the query if execution fails.
By ensuring that the resulting queries align with the structure and limitations of the database, this continual refinement enhances overall accuracy and usefulness.
Prompt template
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
## Request Please write a gremlin query to answer the given question: {{question}} You will be provided with couple relevant vertices, together with their schema and other information. Please choose the most relevant vertex according to its schema and other information to make the gremlin query correct. ## Instructions 1. Here are related vertices and their details: {{schema}} 2. Don't rename properties. 3. Don't change lines (using slash n) in the generated query. ## IMPORTANT Return the results in the following XML format: <Results> <Query>INSERT YOUR QUERY HERE</Query> <Explanation> PROVIDE YOUR EXPLANATION ON HOW THIS QUERY WAS GENERATED AND HOW THE PROVIDED SCHEMA WAS LEVERAGED </Explanation> </Results> |
Comparing the ground truth with queries generated by LLM
Using Anthropic Claude 3.5 Sonnet on Amazon Bedrock as a judge, we put in place an LLM-based assessment system to evaluate the query generation and execution outcomes for Amazon Nova Pro and a benchmark model. The system functions in two main domains:
- Evaluation of queries: Determines accuracy, efficiency, and resemblance to ground-truth queries; computes precise percentages of matching components; and assigns a final score based on predetermined criteria created in collaboration with subject matter experts.
- Execution evaluation: A two-stage evaluation procedure was improved from a single-stage method that was first utilized to compare produced outcomes with ground truth:
- Verification of each item against the ground truth
- Total match percentage calculation
Conclusion
Our approach to tackling the inherent complexities of graph query generation involves managing diverse vertex and edge attributes, reasoning across intricate graph structures, and embedding domain-specific knowledge.
Looking ahead, we aim to enhance the framework’s precision by refining its evaluation process for nested query outputs and optimizing LLM utilization for improved query synthesis.
Drop a query if you have any questions regarding Gremlin and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. How does Amazon Bedrock help generate Gremlin queries?
ANS: – It uses models like Amazon Nova Pro to convert natural language into Gremlin queries using schema and context from the graph database.
2. What are the benefits of automating Gremlin query generation?
ANS: – It saves time, reduces errors, and lets non-technical users query graph data using plain language.
3. How is query accuracy evaluated?
ANS: – Using Anthropic Claude 3.5 Sonnet on Amazon Bedrock, which compares generated queries with ground truth to measure accuracy and performance.

WRITTEN BY Aayushi Khandelwal
Aayushi is a data and AIoT professional at CloudThat, specializing in generative AI technologies. She is passionate about building intelligent, data-driven solutions powered by advanced AI models. With a strong foundation in machine learning, natural language processing, and cloud services, Aayushi focuses on developing scalable systems that deliver meaningful insights and automation. Her expertise includes working with tools like Amazon Bedrock, AWS Lambda, and various open-source AI frameworks.











Comments