

 Login
Login

 October 30, 2025
October 30, 2025|
Voiced by Amazon Polly |
Introduction
From improving customer service to automating content creation, generative AI models are revolutionizing the way businesses operate. Developers can leverage these capabilities with the aid of AWS’s comprehensive suite of generative AI services. However, comprehending and optimizing these models’ fundamental parameters is often necessary to maximize their effectiveness. Three important parameters, Temperature, Top-P, and Top-K, will be demystified in this blog post, along with their functions and how they impact the results of AWS Generative AI models.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Objective
This blog post aims to provide readers with a clear and concise understanding of the Top-P, Top-K, and Temperature parameters in relation to AWS Generative AI models. By the end of this article, you should be able to confidently modify these parameters to manage the originality, variety, and coherence of the content your model generates, producing more reliable and efficient results.
Sampling Parameters' Role in Text Generation
Before delving into specific parameters, it’s essential to understand their purpose.
Language models use probabilities to predict the next most likely token (word or word piece), not the correct answer.
For instance, the model might assign the following to the phrase “The sky is”:
- “blue” → probability of 0.85
- “clear” → 0.10 likelihood
- “falling” → 0.03 likelihood
Outputs become monotonous and robotic if the model consistently selects the option with the highest probability, or “blue.” Controlled randomness is introduced by sampling parameters such as Temperature, Top-P, and Top-K, which contribute to the creation of more imaginative, varied, and human-like text.
Temperature
Before sampling, the temperature parameter determines the softness of the probability distributions.
In essence, it scales the model’s confidence in selecting the subsequent token.
- At low temperatures (0.1–0.3), the model becomes focused and deterministic, which is advantageous for providing factual and reliable responses.
- A medium temperature (e.g., 0.5–0.7) is ideal for a balanced conversational tone, as it adds variation without compromising coherence.
- High temperatures (0.8 to 1.5): Promote creativity and unpredictability; ideal for idea generation, storytelling, and brainstorming.
Top-K
Top-K sampling ignores all other tokens and limits the model to the K most likely tokens at each generation step.
- K = 1: Selects the next token based on probability (no randomness).
- K = 50: Selects one of the 50 most likely choices.
- K = 1000: Sometimes, at the expense of coherence, it permits far more creative expression.
How It Operates
Assume that the model predicts 50,000 potential next words. With Top-K = 40, only the 40 most likely are taken into account, and one is chosen at random from their probabilities. This allows for variation while maintaining the plausibility of responses.
Top-P (Nucleus Sampling)
An alternative to Top-K is Top-P, also known as nucleus sampling.
It chooses the smallest group of tokens whose combined probability is greater than P rather than a predetermined number of tokens.
For instance:
- The model selects tokens that together account for 90% of the probability mass, if Top-P = 0.9.
Because of this, Top-P is adaptive: it expands its scope when the model is uncertain (with many possible continuations) and behaves like Top-K with a small K when it is confident (with a few high-probability tokens).
Selecting Principles
- Top-P = 0.8–0.9: Natural and balanced text production.
- Top-P < 0.5: Highly deterministic; excellent for technical or exact answers.
- Top-P > 0.95: Extremely exploratory and varied.
Architectural Flow in AWS Generative AI
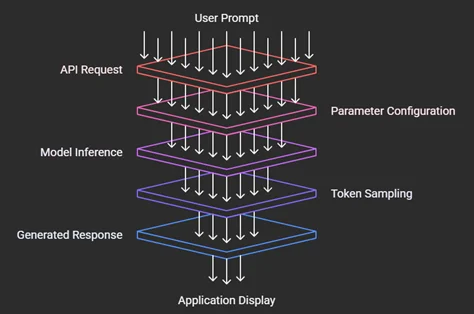
- User Prompt: When a user or application submits a natural language request, such as “Write a summary of this document” or “Generate a creative product description,” the process starts.
- API Request: An API call is used to send the prompt, usually through the AWS SDK or Amazon Bedrock. The large language model (LLM) hosted on AWS infrastructure can be accessed through this layer.
- Parameter Configuration: The model parameters, Top-P, Top-K, and Temperature, are applied prior to inference.
- Creativity and randomness are adjusted by temperature.
- Token selection is restricted by Top-P to a cumulative probability threshold.
- The selection is limited to the most likely K tokens by Top-K.
When combined, they influence the generated text’s tone and behavior.
4. Model Inference: The LLM inference engine (such as Amazon Titan, AI21 Jurassic, or Anthropic Claude) receives the configured request. After processing the input and forecasting potential next tokens, the model starts producing output based on probability distributions.
5. Token Sampling: At each generation stage, the model chooses the best tokens by using the specified sampling parameters. The outputs are guaranteed to be contextually diverse and coherent due to the controlled randomness.
6. Generated Response: Following token generation, the model generates a final structured response that is prepared for return, such as a paragraph, synopsis, response, or original work.
7. Application Display: The user can view or interact with the response after it has been sent back to the application interface, which could be a chatbot, dashboard, or web application.
What Happens Next?
As AWS’s Generative AI stack develops further, developers can anticipate:
- Smarter parameter optimization: depending on the situation, models may automatically modify the sampling parameters.
- User-level presets: AWS Bedrock may provide parameter-tuning profiles such as Creative Mode or Analytical Mode.
- With parameter-aware inference, multi-model orchestration dynamically routes prompts between models (e.g., Titan for summarization, Claude for reasoning).
- For scalable AI pipelines that combine several generation stages, integration with AWS Lambda and AWS Step Functions is required.
Conclusion
Key controls that enable users to influence how AWS Generative AI models behave are Temperature, Top-P, and Top-K.
Gaining precise control over the creative and analytical powers of generative AI through mastery of these parameters opens the door to more complex and significant applications. It’s not just about producing the correct results.
Drop a query if you have any questions regarding AWS Generative AI models and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is the Amazon Bedrock models' default temperature?
ANS: – Each model has its own variations. The majority of AWS-hosted models, such as AI21 Jurassic and Anthropic Claude, have default values of about 0.7, providing a good balance between consistency and creativity.
2. Should I combine Top-K and Top-P?
ANS: – Yes, but make careful use of them. While Top-K restricts candidate tokens, Top-P manages the overall probability mass. You can exert fine-grained control over diversity by combining the two.
3. What occurs if the temperature is set to zero?
ANS: – The model turns completely deterministic, meaning that it will consistently generate the same result for the same prompt.

WRITTEN BY Balaji M
Balaji works as a Research Associate in Data and AIoT at CloudThat, specializing in cloud computing and artificial intelligence–driven solutions. He is committed to utilizing advanced technologies to address complex challenges and drive innovation in the field.










Comments