

 Login
Login

 August 25, 2025
August 25, 2025|
Voiced by Amazon Polly |
Overview
Running scalable, efficient, cost-effective SQL queries across large datasets is essential in modern data platforms. Amazon EMR supports open-source engines like Apache Hive, Presto, and Trino, providing flexibility and performance for data processing and analytics on Amazon S3 and HDFS. This blog overviews these engines, highlights key Amazon EMR features, outlines migration strategies, and offers best practices for effectively managing and tuning workloads.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Apache Hive on Amazon EMR
Apache Hive is a widely used SQL-based data warehouse engine built for batch processing large datasets. On Amazon EMR, Hive supports various file formats (e.g., ORC, Parquet, JSON) and data sources (e.g., HDFS, Amazon S3, Amazon DynamoDB). It is primarily used for ETL, reporting, and interactive queries.
Amazon EMR enhances Hive with features such as:
- ACID transaction support (from EMR 6.1)
- LLAP (Low Latency Analytical Processing) for faster performance
- Optimized EMRFS S3 committers for better write performance
- Integration with AWS Glue Data Catalog or Amazon RDS for metadata management
Amazon EMR Hive benefits from up to 15x faster write performance using the “zero-rename” feature and persistent Tez UI for query monitoring.
Presto and Trino on Amazon EMR
Presto is a distributed SQL query engine designed for interactive analytics over petabyte-scale datasets. Trino, a fork of PrestoSQL, continues this lineage with enhanced capabilities. Both engines are supported in Amazon EMR.
Key features include:
- Memory-based parallel architecture for fast query execution
- Connectors to multiple data sources (Amazon Redshift, Kafka, HDFS, Amazon S3)
- Fine-grained Lake Formation policy enforcement (Presto)
- Iceberg and Delta Lake support (Trino)
- Up to 3.1x better performance on Amazon EMR compared to open-source Trino
Amazon EMR provides Presto and Trino with security features like SSL encryption and LDAP authentication, while Presto Web UI allows users to monitor and troubleshoot queries in real time.
Configuring and Running Workloads
Amazon EMR supports multiple interfaces and orchestration options for running Hive and Presto workloads:
- CLI (Hive CLI, Beeline, Presto CLI)
- JDBC/ODBC (Simba drivers)
- Notebooks (EMR Studio, Zeppelin, Hue)
- AWS orchestration tools (Step Functions, MWAA)
Hive configuration can be customized using hive-site, tez-site, and hive-env configurations. For Presto, tuning is done via coordinator and worker configurations, connectors, and security settings.
Migration Strategy
A successful migration to Amazon EMR involves the following steps:
- Data Migration to Amazon S3
Use tools like distcp, AWS CLI, AWS DataSync, or Snowball to transfer datasets from on-prem HDFS to Amazon S3. Data should be structured for parallel processing and optimized for query performance.
- Hive Metastore Migration
Move on-prem Hive metastores to either Amazon RDS or AWS Glue. This allows multiple Amazon EMR clusters to share metadata and decouples compute from storage.
- Script and Query Updates
Update DDLs to reflect Amazon S3 locations. DMLs typically require minimal changes. Hive external tables are recommended for persistent data access from Amazon S3.
- Security Configuration
Implement authentication using LDAP/Kerberos and authorization using SQL standards or Apache Ranger with Amazon EMR.
Performance Tuning and Best Practices
To achieve optimal performance on Amazon EMR, follow these best practices:
Partitioning and Bucketing
- Use partitions to reduce the data scanned during queries.
- Apply bucketing for frequently filtered high-cardinality columns.
- Combine partitioning and bucketing for significant improvements in performance and cost.
File Formats and Sizes
- Use columnar formats like Parquet for efficient reads.
- Avoid small files; aim for files larger than 128MB.
- Compress data using splittable formats for better parallelism.
Query Tuning
- Use APPROX_DISTINCT() for faster cardinality estimation.
- Limit selected columns to only what’s needed.
- Use LIMIT with ORDER BY to avoid memory-intensive operations.
- Arrange JOIN operations with the smaller table on the right to optimize memory usage.
- Order GROUP BY columns by decreasing cardinality.
Presto vs Amazon Athena vs Amazon Redshift Spectrum
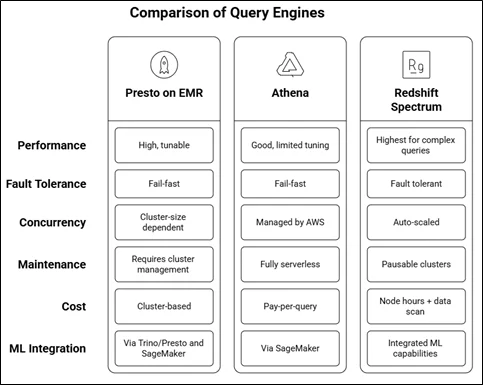
Choose the engine based on query complexity, concurrency needs, and cost model.
Conclusion
By following best practices in partitioning, file formats, and query tuning, businesses can significantly improve query efficiency and reduce costs. With the right engine choice and optimization strategies, Amazon EMR offers scalable foundation for modern data analytics.
Drop a query if you have any questions regarding SQL Analytics and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. What is the advantage of running Hive on Amazon EMR?
ANS: – Amazon EMR provides improved performance, ACID support, and cost optimization features such as spot instances and zero-rename writes.
2. How does Presto on EMR differ from Amazon Athena?
ANS: – Presto on Amazon EMR offers customizable cluster configurations and supports larger, more complex workloads, while Amazon Athena is fully serverless and pay-per-query.
3. Can I use ACID transactions with Hive on Amazon S3?
ANS: – Yes, Hive on Amazon EMR supports ACID transactions with base and delta files and compaction to manage file sizes on Amazon S3.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments