

 Login
Login

 November 12, 2025
November 12, 2025|
Voiced by Amazon Polly |
The rise of generative AI and large language models (LLMs) has transformed how organizations think about data. We’ve entered an era where information is not just stored and retrieved – it’s understood, contextualized and used to generate new insights.
At the heart of this transformation is a new type of data representation: vectors. These high-dimensional numerical embeddings represent the “meaning” of data – whether it’s text, images, audio or code – allowing systems to perform semantic search, recommendations and retrieval-augmented generation (RAG) with remarkable accuracy.
Recognizing this paradigm shift, AWS recently introduced Amazon S3 Vectors, a groundbreaking feature that brings native vector storage and query capabilities directly to Amazon S3 – the most widely used object storage service in the world.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
Why Traditional Storage Isn’t Enough in the Age of AI?
Traditionally, Amazon S3 has been the backbone of data lakes – a scalable, durable and cost-efficient repository for unstructured data. However, while S3 excels at storing raw objects (like documents, images or logs), it wasn’t designed to understand the semantic relationships between those objects.
For example, consider a company that stores millions of product descriptions and customer reviews. A keyword-based search (“wireless headphones”) might miss semantically similar phrases like “Bluetooth earbuds.” AI systems, on the other hand, rely on vector embeddings to measure similarity in meaning rather than in literal text matches.
Until now, storing and querying vectors required a separate vector database (like Pinecone or OpenSearch). This introduced complexity, data movement and cost overhead, especially for organizations that already had petabytes of data sitting in S3.
What is Amazon S3 Vectors?
Amazon S3 Vectors (currently in preview) adds vector embedding storage and search functionality natively within Amazon S3. It enables customers to store, manage and query vector representations of data alongside their existing S3 objects – eliminating the need to move data into specialized vector databases.
In essence, S3 Vectors turns your data lake into a vector-aware semantic repository.
Key Capabilities
- Native Vector Storage
Store vector embeddings directly in S3 alongside your data objects, with full durability and scalability.
- Similarity Search (k-NN Queries)
Perform vector similarity searches (cosine similarity, Euclidean distance) directly within S3 to find semantically related items.
- Integration with Bedrock and SageMaker
Generate embeddings using foundation models in Amazon Bedrock or SageMaker JumpStart, then store and query them in S3 Vectors.
- RAG Pipeline Simplification
Build retrieval-augmented generation (RAG) systems where documents and their embeddings live in the same S3 bucket – reducing latency, cost and architecture complexity.
- Cost-Efficiency and Durability
Take advantage of S3’s pricing model and 99.999999999% durability, while paying only for what you store – not for database clusters or dedicated compute.
How It Works
When you enable S3 Vectors on a bucket, each stored object can have an associated vector embedding (an array of floating-point numbers) attached as metadata.
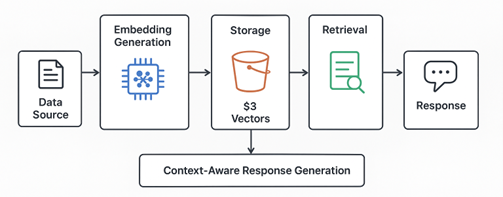
Flow of context-aware response generation using embeddings and vector storage.
- Data Ingestion
Upload your documents, images or videos to Amazon S3 as usual.
- Embedding Generation
Use an embedding model (for instance, Titan Embeddings on Amazon Bedrock) to convert the content into vector representations.
- Store Embeddings in S3 Vectors
Store the generated vectors as part of your S3 object metadata or in a designated “vector index” within the same bucket.
- Perform Queries
Run similarity queries directly against your S3 vector index. For example:
- Find the top 10 most semantically similar documents to a given query vector.
- Retrieve related product descriptions, images or code snippets.
- Integrate with Downstream Services
Use AWS Lambda, SageMaker or Bedrock agents to build workflows where the retrieved objects are used in generative or analytical tasks.
Why It Matters
- No More Data Movement
Previously, AI developers needed to extract data from S3, compute embeddings and upload them into a vector database. This added friction and cost.
With S3 Vectors, data remains where it belongs, inside the data lake, enabling seamless AI integration without redundant storage.
- Lower Total Cost of Ownership (TCO)
Traditional vector databases can be expensive to operate at scale. By leveraging S3’s pay-per-GB storage model, organizations can reduce infrastructure costs significantly.
- Scalability and Durability
As S3 already handles exabytes of data globally, extending this to vector workloads ensures reliability and near-infinite scalability.
- Simplified RAG and Search Pipelines
Developers can now implement semantic search and context retrieval directly from their data lake, enabling the faster development of chatbots, recommendation systems and knowledge assistants.
- Seamless AWS Ecosystem Integration
S3 Vectors integrates naturally into existing AWS architectures, working seamlessly with Lambda, Glue, Athena, Bedrock and SageMaker. This native integration drastically simplifies AI-ready data architectures.
Use Cases
- Enterprise Knowledge Search
Index corporate documents, meeting transcripts and reports for semantic search using natural language queries.
- E-Commerce Recommendations
Match users with similar products or reviews based on embedding similarity rather than keywords.
- Customer Support Bots (RAG)
Feed the most relevant internal documentation snippets into LLM prompts to improve chatbot accuracy and reduce hallucinations.
- Media and Image Retrieval
Search visually similar images or video clips using embeddings from computer vision models stored directly in S3.
- Code and API Search
Store embeddings of code snippets or API responses for semantic code retrieval across repositories.
Challenges and Considerations
While S3 Vectors introduces immense potential, it’s still in preview – meaning some limitations and best practices are evolving:
- Query Performance: Native vector search within S3 may not yet match the sub-millisecond latency of specialized databases for real-time applications.
- Index Management: Efficiently managing, updating and deleting vectors at scale will require governance and lifecycle policies.
- Data Privacy: Storing embeddings (which may contain latent information about the source data) should comply with enterprise data governance policies.
That said, AWS’s approach to unifying storage, metadata and semantic representation is likely to evolve quickly, with optimizations for scale and latency in upcoming releases.
The Bigger Picture
Amazon S3 Vectors is not just another feature – it’s a strategic inflection point for data architecture in the AI era.
By bringing vector semantics natively into the world’s most trusted object store, AWS is collapsing the traditional boundary between data storage and AI understanding. It enables a future where every enterprise data lake becomes an AI-ready knowledge repository, capable of powering search, analytics and generative experiences directly from the source.
As organizations race to operationalize AI, S3 Vectors stands out as a foundational building block, bridging the gap between traditional cloud storage and intelligent data systems.
The Future of Amazon S3 Vectors
Amazon S3 Vectors mark a significant leap forward in how we store and access information. It democratizes vector search, simplifies AI architectures and empowers organizations to unlock the full semantic value of their data, all while leveraging the scalability, security and reliability of Amazon S3.
The next generation of intelligent data lakes has officially arrived.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Nitin Kamble
Nitin Kamble is a Subject Matter Expert and Champion AAI at CloudThat, specializing in Cloud Computing, AI/ML, and Data Engineering. With over 21 years of experience in the Tech Industry, he has trained more than 10,000 professionals and students to upskill in cutting-edge technologies like AWS, Azure and Databricks. Known for simplifying complex concepts, delivering hands-on labs, and sharing real-world industry use cases, Nitin brings deep technical expertise and practical insight to every learning experience. His passion for bike riding and road trips fuels his dynamic and adventurous approach to learning and development, making every session both engaging and impactful.











Comments