

 Login
Login

 December 2, 2025
December 2, 2025|
Voiced by Amazon Polly |
Introduction
Data is essential to modern business. Businesses are collecting more data than ever before through IoT sensor data, e-commerce transactions, and other sources. One well-liked option for managing the flood of real-time data is Amazon DynamoDB. It is a great choice for mission-critical applications since it is fully controlled, incredibly scalable, and offers single-digit millisecond performance.
Yet, there’s a shared obstacle: while Amazon DynamoDB excels at processing transactions, it isn’t well-suited for analytics. Executing complex queries, producing reports, or aggregating data directly on Amazon DynamoDB can be expensive and slow. To circumvent this, companies end up duplicating their operational data into another analytics environment.
That is where Amazon S3 Tables step in. By streaming Amazon DynamoDB table data into Amazon S3 Tables in Apache Iceberg format, companies can achieve near real-time analytics without compromising the performance of their operational systems. This blog addresses common questions you may have, outlines the benefits the solution offers, explains how it operates, and provides best practices for deployment.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Why Stream DynamoDB Data to Amazon S3 Tables?
Workload isolation is the main argument in Favor of shifting Amazon DynamoDB data to Amazon S3. OLTP workloads were intended to be driven by Amazon DynamoDB. The OLAP category is where analytics belong. Combining the two on the same platform may result in higher costs and reduced performance.
Amazon S3 Tables fill that gap. They are revolutionary for the following reasons:
- Performance: Compared to unmanaged data lakes, Amazon S3 Tables can execute up to three times faster due to their efficient handling of metadata, indexing, and query optimization.
- Scalability: Petabytes of data may be processed and stored with virtually no limits.
- Flexibility: Query data using SQL across services such as Amazon Athena, Amazon Redshift, Amazon QuickSight, or even Apache Spark.
- Data evolution: Iceberg tables provide the flexibility to perform historical analysis without the burden of managing complex data administration, enabling schema evolution and time-travel queries.
- Cost effectiveness: Offloading analytics queries from Amazon DynamoDB saves costs, as Amazon DynamoDB is charged based on read and write throughput.
In effect, this architecture enables you to maintain Amazon DynamoDB’s position as a blindingly fast transactional database while still gaining access to powerful, real-time insights.
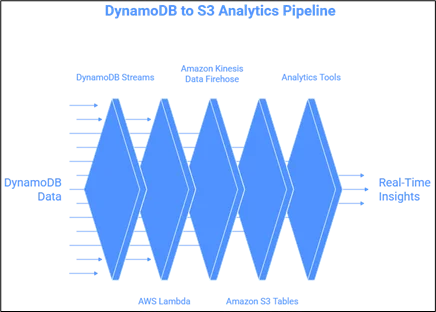
How Does the Architecture Work?
Additionally, it depends on the serverless, fully managed pipeline, which needs little setup or maintenance. The following illustrates the workflow:
1. Amazon DynamoDB Streams: Almost instantly, anything you add, edit, or delete from your Amazon DynamoDB table is committed.
2. AWS Lambda: A function processes the data from the stream and applies any lightweight transforms that are required to get them ready for delivery.
- Writing, batching, and compressing the data to your Amazon S3 bucket is done via Amazon Kinesis Data Firehose.
- Amazon S3 Tables: Provides analytics with rapid access to data stored in Apache Iceberg format.
5. Analytics Tools: QuickSight BI dashboards, Amazon Redshift advanced analytics, and Amazon Athena ad hoc querying of Iceberg data warehouses.
You are not required to build specialized ETL operations or struggle with infrastructure due to this architecture. It scales smoothly with your workload and is plug-and-play.
Real-World Use Cases
To put the impact into perspective, frame the scenarios:
- Healthcare and Life Sciences: Hospitals and health-tech providers can stream patient monitoring data from Amazon DynamoDB into Amazon S3 Tables to analyze vital sign trends in near real time. This enables the quick identification of abnormalities, such as abrupt increases in heart rate, without interfering with critical care systems.
- Logistics and Supply Chain: Amazon DynamoDB can continuously broadcast shipment and sensor changes into Amazon S3 tables for a worldwide logistics organization. By doing this, the business can monitor fleet efficiency, spot delivery bottlenecks, and forecast regional delays. To enhance route optimization, analysts can then use Athena to query past delivery trends.
- Banking Operations and Compliance: For real-time compliance checks, banks can utilize this pipeline to transport transaction audit logs from Amazon DynamoDB into Amazon S3 Tables. When required for reporting or investigations, auditors can quickly recreate previous financial activity states, as Amazon S3 Tables preserve organized, time-stamped records.
- Gaming: Game developers can monitor player gameplay, detect signs of churn, or track engagement without compromising the game experience.
It demonstrates how the streaming trend enables data-driven decision-making, enhances consumer experiences, and provides visibility into business operations.
Best Practices for Implementation
Bear these reminders in mind before you put this pattern into practice:
- Schema design: Plan your mapping of Amazon DynamoDB-to-Amazon S3 diligently. Leverage the schema evolution of Iceberg for flexibility.
- Partitioning: Create partitions in Amazon S3 Tables to enhance query efficiency (for example, by date or region).
- Monitoring: Establish Amazon CloudWatch alarms for AWS Lambda and AWS Firehose to ensure reliability and promptly detect delivery failures.
- Cost awareness: Track AWS Lambda function invocations, AWS Firehose delivery, and Amazon Athena query costs. Buffer parameter and query rate tuning will allow you to save money.
- Security and compliance: Utilize AWS IAM roles, encryption, and fine-grained access controls to safeguard your sensitive data.
Conclusion
By harmonizing the capabilities of Amazon DynamoDB for high-velocity transactions and the analytics capabilities of Amazon S3 Tables, you can construct a data pipeline that scales, remains financially prudent, and is future-proof.
This is not just a technical upgrade; it’s how you close the distance between operations and intelligence. From e-commerce portals to fraud detection, querying live operational data in near real time gives teams the ability to act sooner and make better decisions.
And should your business seek to extract the highest value from your Amazon DynamoDB data, embracing this streaming mindset represents the future-proof investment. By letting AWS do the heavy lifting, you have time to focus where it matters most: extracting insights and driving business results.
Drop a query if you have any questions regarding Amazon DynamoDB or Amazon S3 and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What are the primary advantages of utilizing Amazon S3 Tables as opposed to exporting data straight to Amazon S3?
ANS: – Simple Amazon S3 outputs, such as CSV or JSON, lack structure and are not optimized for performance. You benefit from using Amazon S3 Tables in Iceberg style.
• Metadata management: File and partition tracking is no longer done by hand.
Adding or removing columns without disrupting queries is known as schema evolution.
• Time-travel queries: These are very useful for auditing and compliance since they allow you to query previous states of your data.
• Optimized queries: Partition pruning and indexing make Amazon Athena or Amazon Redshift queries execute more quickly.
For instance, your analysts can easily conduct a time-travel query without taking separate snapshots if they wish to see how customer orders appeared before a significant website upgrade.
2. To what extent is the streaming pipeline real-time?
ANS: – The solution provides near real-time analytics. Depending on the AWS Firehose buffering settings, Amazon DynamoDB Streams gather data instantly and transfer it to Amazon S3 with delays typically measured in seconds to minutes.
This latency is more than sufficient for most analytics use cases, such as fraud detection, trend monitoring, and dashboard creation. You might think about using Amazon Kinesis Data Streams directly if your use case requires actual sub-second streaming (such as high-frequency trading).
3. In which typical use cases does this pattern provide the greatest benefit?
ANS: – The following are a few of the common scenarios:
- Business intelligence: Real-time dashboards that monitor KPIs, sales metrics, or customer engagement.
- Operational monitoring: keeping tabs on customer transactions, error reports, and system health.
- Data science and machine learning: supplying Amazon SageMaker with clear, organized Iceberg tables for predictive modelling.
- Cost optimization: By moving complex queries to Amazon Athena or Amazon Redshift, Amazon DynamoDB expenses can be decreased.

WRITTEN BY Akanksha Choudhary
Akanksha works as a Research Associate at CloudThat, specializing in data analysis and cloud-native solutions. She designs scalable data pipelines leveraging AWS services such as AWS Lambda, Amazon API Gateway, Amazon DynamoDB, and Amazon S3. She is skilled in Python and frontend technologies including React, HTML, CSS, and Tailwind CSS.











Comments