

 Login
Login

 September 1, 2025
September 1, 2025|
Voiced by Amazon Polly |
Introduction
Apache Kafka has become a go-to solution for building high-throughput, real-time streaming pipelines. It enables organizations to ingest, process, and route data streams across distributed systems with low latency. Managing Kafka infrastructure, particularly as scale and complexity grow, can become a significant operational challenge despite its strengths.
AWS provides Amazon Managed Streaming for Apache Kafka (Amazon MSK) to address this. This fully managed Kafka service offloads cluster provisioning, patching, and scaling, allowing teams to focus more on application development than infrastructure management.
However, once data is streaming into Kafka topics, organizations must consume and route this data to downstream destinations like data lakes, warehouses, or storage services. Traditionally, Kafka Connect has been used for this purpose. While effective, it introduces its own operational complexities around scaling, fault tolerance, and custom connector development.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Challenges with Kafka Connect
Though Kafka Connect is widely adopted, it poses several limitations that become more apparent as data velocity and volume increase:
- High Maintenance: Requires managing and scaling connector infrastructure, writing custom delivery logic, and keeping track of versioning and deployments.
- Scalability Issues: In workloads with unpredictable spikes—like gaming or streaming—Kafka Connect can become a bottleneck, often requiring pre-emptive over-provisioning to avoid data loss.
- Inefficient Scaling: Scaling Kafka Connect to handle increasing load involves provisioning additional nodes, which takes time and may incur unnecessary costs.
- Migration Difficulties: Transitioning from Kafka Connect to alternative solutions can be complex, especially when historical data continuity is critical.
Furthermore, Kafka Connect typically demands continuous tuning and monitoring, diverting engineering focus from innovation to infrastructure upkeep.
A Serverless Alternative: Amazon MSK + Data Firehose
To simplify this workflow, AWS introduced a native integration between Amazon MSK and Amazon Data Firehose. This integration, launched in September 2023, provides a serverless, fully managed solution to stream Kafka data directly to destinations like Amazon S3, without the need to develop or maintain custom connectors.
Amazon Firehose automates the reading, transformation, and delivery of streaming data, scaling seamlessly based on load. This integration eliminates the operational and developmental effort otherwise associated with Kafka Connect.
Initially, Amazon Firehose could only begin consuming data from the time of stream creation. This made it challenging for customers needing:
- To migrate from Kafka Connect while preserving historical data.
- To capture complete topic data from the beginning for analysis or reprocessing.
To address this, AWS introduced a timestamp-based offset selection feature, giving users greater control over where Firehose should start consuming data from a Kafka topic.
Flexible Starting Point Options
Users can now choose from three starting positions when creating a Firehose stream:
- From stream creation time (default behaviour).
- From the earliest available message on the Kafka topic,
- From a custom timestamp, allowing precise control over data ingestion start points.
This added flexibility enables:
- Replay and backfill of historical data.
- Seamless transitions from Kafka Connect without interrupting producers.
- Reduced chances of data gaps or duplication during migration.
Use Case 1: Migrating from Kafka Connect to Amazon Data Firehose
Here’s how to migrate with minimal downtime:
- Determine the latest offset timestamp processed by Kafka Connect.
- Stop Kafka Connect ingestion to avoid duplicate writes.
- Use a script (e.g., get_latest_offsets.py) to retrieve timestamps for each partition.
- Set up an Amazon Data Firehose stream using MSK as the source and Amazon S3 as the destination.
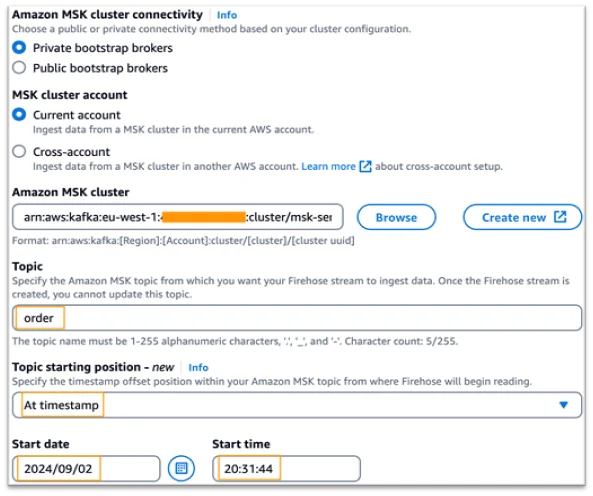
- During stream creation, choose the “At Timestamp” option and provide the previously noted timestamp.
- Validate that data is flowing correctly into the designated Amazon S3 bucket.
Use Case 2: Creating a New Data Pipeline
To build a new streaming pipeline:
- Create an Amazon Data Firehose stream from an MSK topic to Amazon S3.
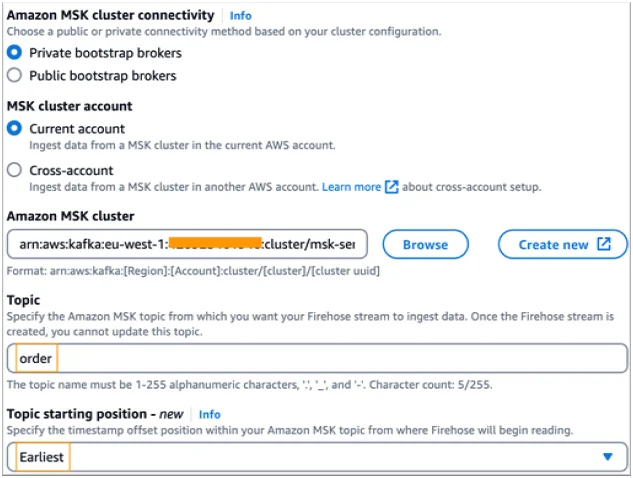
- Select “Earliest” as the starting position to capture the full topic history.
- Define destination settings to point to your Amazon S3 bucket.
- Monitor delivery using Amazon S3 folder structure formatted as YYYY/MM/dd/HH.
In both scenarios, necessary AWS IAM roles can be configured manually or auto-generated during setup to allow Amazon Data Firehose to access Amazon MSK and Amazon S3.
Architecture Overview & Prerequisites
To implement this solution, you’ll need:
- Access to AWS services: Amazon MSK, Amazon Data Firehose, Amazon S3, AWS IAM, and optionally Amazon EC2.
- A Kafka topic (e.g., order) in your Amazon MSK cluster.
- If migrating, an existing Kafka Connect setup.
- An Amazon EC2 instance for running admin commands or checking consumer offsets.
For testing, AWS offers a GitHub repository with sample scripts that generate simulated clickstream data from an e-commerce platform.
Verifying Data Delivery
Once your stream is configured:
- Navigate to the specified Amazon S3 bucket.
- Review the folder structure and ensure data records appear under the correct timestamps.
- Use Amazon CloudWatch to track metrics and troubleshoot any delivery issues.
Cleaning Up Resources
After testing, unused Amazon Data Firehose streams, Amazon EC2 instances, and Amazon S3 data should be deleted to avoid incurring charges.
Conclusion
The integration between Amazon MSK and Amazon Data Firehose provides a powerful, fully managed alternative to Kafka Connect for streaming data to Amazon S3.
Drop a query if you have any questions regarding Amazon MSK or Amazon Data Firehose and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Does Amazon Data Firehose support the transformation of the Kafka data before writing to Amazon S3?
ANS: – Yes. Amazon Data Firehose supports data transformation using AWS Lambda. You can preprocess, filter, or reformat the data before it is delivered to the destination.
2. How do I verify that Amazon Data Firehose delivers my data correctly?
ANS: – Check the destination (e.g., Amazon S3) to ensure the folder structure and data records appear as expected. You can also monitor delivery metrics and logs via Amazon CloudWatch for deeper troubleshooting.
3. What happens if my Kafka topic has a sudden spike in data volume?
ANS: – Amazon Data Firehose automatically scales based on the data volume, so you don’t need to worry about manual provisioning or managing throughput like you would with Kafka Connect.

WRITTEN BY Daneshwari Mathapati
Daneshwari works as a Data Engineer at CloudThat. She specializes in building scalable data pipelines and architectures using tools like Python, SQL, Apache Spark, and AWS. She is proficient in working with tools and technologies such as Python, SQL, and cloud platforms like AWS. She has a strong understanding of data warehousing, ETL processes, and big data technologies. Her focus lies in ensuring efficient data processing, transformation, and storage to enable insightful analytics.











Comments