

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Introduction
Traditional search engines rely heavily on keyword matching. If a user searches for “best laptop for programming,” a keyword-based search system looks for documents containing the exact words “best,” “laptop,” and “programming.” While this approach works in many cases, it often struggles to understand the actual meaning behind a query.
For example, a user searching for “affordable notebook for developers” may expect results similar to “budget laptop for programmers.” Although both phrases express the same intent, they contain different words. A traditional search system may fail to recognize this relationship.
This challenge led to the rise of semantic search, a technique that focuses on understanding content meaning rather than simply matching keywords. At the heart of semantic search lies a powerful concept known as embeddings.
In this blog, we will explore what embeddings are, how text is converted into vectors, and why they have become a fundamental building block of modern AI applications.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Embeddings
Embeddings are numerical representations of data that capture its meaning and relationships.
Machine learning models cannot directly understand text. Before a model can process language, words and sentences must be converted into a format that computers can work with, numbers.
An embedding transforms text into a list of numbers, often called a vector. Unlike simple numerical encodings, embeddings preserve semantic relationships between words, phrases, and documents.
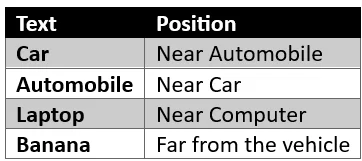
Consider the following terms:
- Car
- Automobile
- Vehicle
- Banana
A well-trained embedding model will place “car,” “automobile,” and “vehicle” close to one another in vector space because they share similar meanings. “Banana” will be positioned much farther away because it belongs to a different concept.
This ability to capture meaning is what makes embeddings so valuable.
How Text Is Converted into Vectors?
The process of generating embeddings involves multiple steps.
Step 1: Text Input
The system receives a piece of text such as:
Artificial Intelligence is transforming industries.
Step 2: Tokenization
The text is broken into smaller units called tokens.
Example:
[“Artificial”, “Intelligence”, “is”, “transforming”, “industries”]
Modern language models may further split words into subwords to handle vocabulary efficiently.
Step 3: Neural Network Processing
The tokens are passed through a trained language model, such as:
- BERT
- Sentence Transformers
- OpenAI Embedding Models
- Gemini Embedding Models
During training, these models learn patterns, context, and relationships between words from massive datasets.
Step 4: Vector Generation
The model produces a dense numerical representation.
Example:
[0.24, -0.67, 0.18, 0.91, …]
The vector may contain hundreds or even thousands of dimensions.
Although humans cannot interpret these numbers directly, the model uses them to represent the semantic meaning of the text.
Understanding Vector Space
A useful way to think about embeddings is to imagine a multidimensional map.
Each word, sentence, or document occupies a position in this space.
For example:
The closer two vectors are, the more similar their meanings.
This allows machines to compare content based on semantics rather than exact wording.
Measuring Similarity Between Embeddings
Once text is converted into vectors, we need a way to determine how similar two pieces of text are.
One of the most common techniques is Cosine Similarity.
Cosine similarity measures the angle between two vectors.
- Similar meaning → Similar direction → Higher score
- Different meaning → Different direction → Lower score
Example:
Query:
Best smartphone for photography
Document A:
Top mobile phones with excellent camera quality
Document B:
Benefits of regular exercise
Even though Document A does not contain the exact keywords from the query, its embedding will be closer to the query vector because the meanings are related.
As a result, semantic search correctly identifies Document A as the better match.
Embeddings in Semantic Search
The workflow of semantic search typically follows these steps:
Indexing Phase
- Collect documents.
- Generate embeddings for each document.
- Store embeddings in a vector database.
Popular vector databases include:
- Pinecone
- Weaviate
- Chroma
- Milvus
- pgvector for PostgreSQL
Search Phase
- User submits a query.
- Generate an embedding for the query.
- Compare the query vector against stored document vectors.
- Retrieve the most similar results.
Because the comparison is based on meaning, relevant content can be discovered even when exact keywords are missing.
Real-World Applications of Embeddings
Semantic Search Engines
Search systems can understand user intent and return relevant results despite differences in wording.
Example:
Query: How to fix a slow computer?
Relevant result:
Ways to improve PC performance
Recommendation Systems
Streaming platforms and e-commerce websites use embeddings to identify similar products, movies, or content.
Users who viewed one item can be recommended semantically related items.
Retrieval-Augmented Generation (RAG)
Modern AI assistants often use embeddings in RAG architectures.
The process involves:
- Converting documents into embeddings.
- Storing them in a vector database.
- Retrieving relevant content based on user queries.
- Supplying that content to an LLM for accurate responses.
This approach helps reduce hallucinations and improve response quality.
Chatbots and Virtual Assistants
Embeddings enable chatbots to understand how users express the same request in different ways.
For example:
- “Reset my password”
- “I can’t log into my account”
- “Help me recover access”
All three requests may be mapped to similar support resources because their embeddings capture related intent.
Why Embeddings Matter?
Embeddings have transformed how machines process language. Instead of relying solely on keyword matching, systems can now understand context, intent, and relationships between concepts.
This capability powers many of today’s AI-driven applications, including semantic search, recommendation engines, intelligent chatbots, and Retrieval-Augmented Generation systems.
As organizations continue to build AI-powered solutions, embeddings serve as the bridge between human language and machine understanding. By converting text into meaningful vectors, they allow systems to retrieve information more accurately and deliver experiences that feel significantly more intelligent.
Conclusion
Embeddings are one of the most important innovations in modern Natural Language Processing. They convert text into numerical vectors that capture semantic meaning, enabling machines to compare and retrieve information based on understanding rather than exact word matches.
Whether powering a search engine, a recommendation platform, or an enterprise AI assistant, embeddings provide the foundation for semantic search and intelligent information retrieval. As AI applications continue to evolve, understanding embeddings is becoming an essential skill for developers and data professionals alike.
Drop a query if you have any questions regarding Embeddings, and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. Why are embeddings important?
ANS: – They help AI systems understand relationships between words, sentences, and documents.
2. How does semantic search use embeddings?
ANS: – It compares vector similarities to find results based on meaning rather than exact keywords.

WRITTEN BY Sonam Kumari
Sonam is a Software Developer at CloudThat with expertise in Python, AWS, and PostgreSQL. A versatile developer, she has experience in building scalable backend systems and data-driven solutions. Skilled in designing APIs, integrating cloud services, and optimizing performance for production-ready applications, Sonam also leverages Amazon QuickSight for analytics and visualization. Passionate about learning and mentoring, she has guided interns and contributed to multiple backend projects. Outside of work, she enjoys traveling, exploring new technologies, and creating content for her Instagram page.











Comments