

 Login
Login

 October 30, 2025
October 30, 2025|
Voiced by Amazon Polly |
Overview
Change Data Feed (CDF) in Delta Lake represents a powerful capability that enables organizations to track and process row-level changes in their data tables efficiently. This feature eliminates the need to reprocess entire datasets, enabling incremental data processing and making it an essential tool for modern data architecture.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Change Data Feed
Change Data Feed is a native mechanism in Delta Lake that captures fine-grained changes, inserts, updates, and deletes, at the row level directly within data tables. When enabled on a Delta table, the runtime records “change events” for all data written into the table, including the row data along with metadata indicating whether the specified row was inserted, deleted, or updated.
Unlike traditional methods that scan entire tables or compare timestamps, CDF allows systems to retrieve only the modified rows efficiently. For example, instead of comparing two multi-terabyte versions of a table, you can instantly access just the handful of rows that were updated.
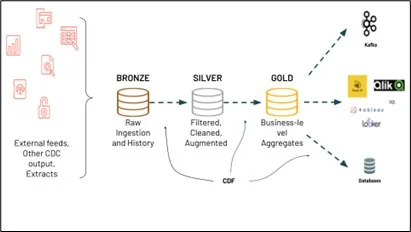
How Delta Lake Implements Change Data Feed
Delta Lake’s implementation of CDF is a logical abstraction constructed from multiple components rather than explicit change records stored in physical storage. The data, once committed, is recorded in the transaction log within the _delta_log directory, which references the data parts and can be read as a stream of record batches. Delta Lake utilizes min/max statistics to skip data files that do not contain relevant changes, thereby significantly reducing the amount of data that needs to be read.
Enabling Change Data Feed
To enable CDF on a Delta table, you need to set the table property during table creation or alter an existing table. Here’s how to create a table with CDF enabled:
|
1 2 3 |
spark.sql( "CREATE TABLE people (first_name STRING, age LONG) USING delta TBLPROPERTIES (delta.enableChangeDataFeed = true)" ) |
Once enabled, you can query the change data feed to retrieve row-level changes between different versions of your table.
Reading Change Data Feed
CDF supports both streaming and batch queries, providing flexibility in how you consume change data. For streaming queries, you set the readChangeFeed option to true:
|
1 2 |
spark.readStream.option("readChangeFeed", "true") .table("myDeltaTable") |
For batch queries, you must specify a starting version:
|
1 2 3 4 5 |
spark.read.format("delta") .option("readChangeFeed", "true") .option("startingVersion", 0) .table("people") .show() |
The output includes the original columns plus additional metadata columns: _change_type (insert, update, delete), _commit_version, and _commit_timestamp.
Key Use Cases for Change Data Feed
- Incremental ETL/ELT Operations: CDF improves Delta Lake performance by processing only row-level changes following initial MERGE, UPDATE, or DELETE operations. This acceleration significantly simplifies ETL and ELT workflows, eliminating the need to reprocess entire tables.
- Real-Time Analytics and BI: Organizations can create up-to-date, aggregated views of information for business intelligence and analytics without reprocessing full underlying tables. Instead, they update only where changes have come through, enabling real-time analytics pipelines that respond immediately to data updates.
- Downstream System Integration: CDF enables sending change data to downstream systems, such as Kafka or RDBMS, which can use it to process data in later stages of data pipelines incrementally. This capability is essential for building modern, event-driven architecture.
- Audit Trail and Compliance: Capturing the change data feed as a Delta table provides perpetual storage and efficient query capability to see all changes over time, including when deletes occur and what updates were made. This functionality empowers audit and compliance solutions that require complete historical change tracking.
Implementing CDF for Incremental Updates
One practical application of CDF is maintaining downstream aggregations incrementally. Consider a scenario where you track cumulative purchases by customers and update this aggregation on a daily basis. With CDF enabled on the source table, you can efficiently process only the changed records rather than recalculating aggregations from scratch. This approach dramatically reduces processing time and computational costs, especially for large-scale data operations.
Conclusion
Delta Lake’s Change Data Feed revolutionizes how organizations handle incremental data processing by providing efficient, scalable, and reliable row-level change tracking.
Drop a query if you have any questions regarding Delta Lake’s Change Data Feed and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Does Change Data Feed work with existing Delta tables?
ANS: – Yes, you can enable CDF on existing Delta tables by altering the table properties, but it will only capture changes that occur after enablement, not historical data.
2. What is the performance impact of enabling Change Data Feed?
ANS: – Enabling CDF has an insignificant impact on data insertion operations, while providing substantial benefits for downstream processing by eliminating the need to scan entire tables for changes.

WRITTEN BY Anusha
Anusha works as a Subject Matter Expert at CloudThat. She handles AWS-based data engineering tasks such as building data pipelines, automating workflows, and creating dashboards. She focuses on developing efficient and reliable cloud solutions.










Comments