

 Login
Login

 September 1, 2025
September 1, 2025|
Voiced by Amazon Polly |
Introduction
Embeddings are essential in natural language processing (NLP) and machine learning (ML), where they transform text into high-dimensional numerical vectors. This transformation helps capture both the meaning (semantic relationships) and structure (syntactic relationships) of the text using ML algorithms. These vector representations enable various applications like information retrieval, text classification, and other NLP tasks.
Amazon Titan Text Embeddings is a model designed to convert natural language into vector representations, from individual words to full documents. These embeddings can be leveraged for semantic search, personalization, and content clustering tasks.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Key Concepts
Some key concepts include:
- Numerical representation of text (vectors) captures semantics and relationships between words
- Detailed embeddings enable effective comparison of text similarity
- Multilingual embedding systems provide models with the ability to process and represent semantic content consistently, independent of language barriers
How Text is Converted into Vectors
Various techniques exist to transform a sentence into a numerical vector. A widely used method involves generating word embeddings using algorithms like Word2Vec, GloVe, or FastText, combining these word-level vectors to represent the entire sentence.
Large language models (LLMs) such as BERT or GPT offer contextual sentence embeddings. These models utilize Transformer-based deep learning architectures to understand better the context and relationships among words within a sentence.
Why We Need an Embeddings Model
Vector embeddings play a critical role in helping large language models (LLMs) understand the semantic depth of language. They improve the effectiveness of numerous natural language processing (NLP) tasks, including sentiment detection, entity recognition, and text categorization. By capturing the underlying meaning and context of text, embeddings enable models to generate more accurate and relevant outputs across a wide range of applications.
In addition to semantic search, embeddings are essential for Retrieval Augmented Generation (RAG), where they help improve the accuracy of prompts by retrieving relevant context from external data sources. The embeddings must be stored in a database with vector search capabilities to implement this effectively. Amazon Titan Text Embeddings is optimized for such use cases, converting text into numerical vectors that allow precise retrieval of relevant information from vector databases. This technique empowers businesses to extract maximum benefit from their private data repositories while working with base AI models.
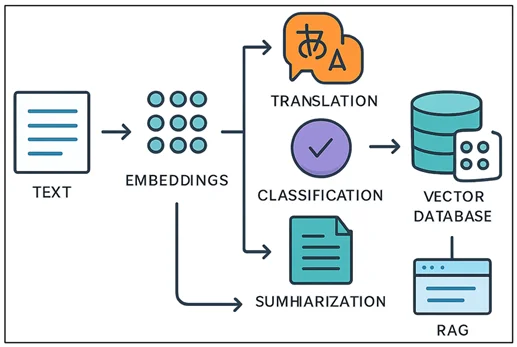
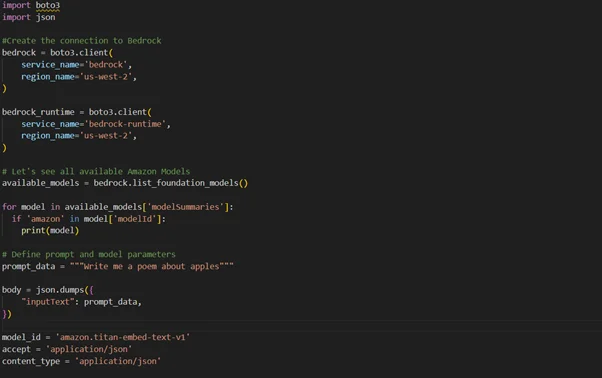
Implementation with AWS SDK
Amazon Titan Text Embeddings is a fully managed, serverless solution through Amazon Bedrock. It can be accessed using the Amazon Bedrock REST API or AWS SDK. To generate embeddings, you must provide the input text and the modelId parameter, specifying the Amazon Titan Text Embeddings model.
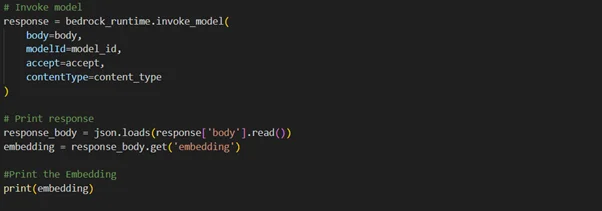
Output

Features of Amazon Titan Text Embeddings
Amazon Titan Text Embeddings supports input sizes of up to 8,000 tokens, making it versatile enough to handle anything from single words and short phrases to full-length documents, depending on your needs. It generates output vectors with a dimensionality of 1,536, offering high accuracy while maintaining low latency and cost-efficiency
Multilingual Support
Amazon Titan Text Embeddings enables creating and querying text embeddings in more than 25 languages, allowing you to support multilingual use cases without the need to manage separate models for each language. This simplifies deployment and broadens the applicability of your solutions across diverse linguistic contexts.
Using a single model trained on multiple languages offers several key advantages:
- Broader reach – By supporting more than 25 languages natively, your applications can effectively serve international users and handle a wide range of multilingual content.
- Consistent performance – A unified model ensures reliable and uniform results across languages, eliminating the need for individual language optimization.
- Multilingual query support – You can query embeddings in any supported languages, enabling flexible and inclusive search and analysis capabilities.
Supported Languages
The following languages are supported:
- Arabic
- Chinese (Simplified)
- Chinese (Traditional)
- Czech
- Dutch
- English
- French
- German
- Hebrew
- Hindi
- Italian
- Japanese
- Kannada
- Korean
- Malayalam
- Marathi
- Polish
- Portuguese
- Russian
- Spanish
- Swedish
- Filipino Tagalog
- Tamil
- Telugu
- Turkish
Using Amazon Titan Text Embeddings with LangChain
LangChain is a widely adopted open-source solution that eases the construction of generative AI-driven applications and their supporting components. It features a BedrockEmbeddings client, which provides a simplified interface by wrapping the Boto3 SDK with an abstraction layer, making integrating Amazon Bedrock embeddings into your workflows easier.
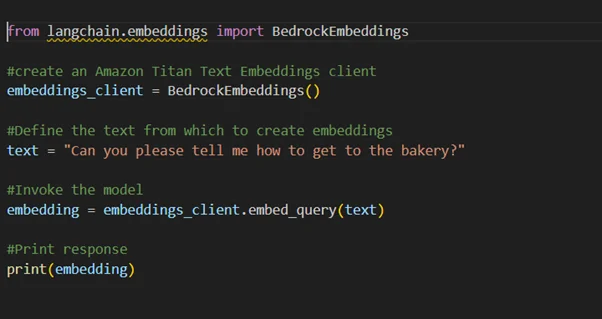
Use Cases
While Retrieval Augmented Generation (RAG) is currently the most common application of embeddings, there are several other valuable use cases where embeddings can be effectively leveraged:
- Personalized Recommendations – Embeddings can be used to suggest vacation spots, vehicles, colleges, or other products by matching user preferences with similar options based on semantic similarity.
- Data Management – When data sources lack a clear mapping but include descriptive text, embeddings can help detect duplicate or related records by comparing the semantic meaning of the descriptions.
- Application Portfolio Rationalization – In scenarios such as mergers or acquisitions, embeddings enable semantic matching of applications across organizations, helping to identify overlapping or redundant software for consolidation quickly.
- Content Grouping – Embeddings make categorizing and organizing similar content easier, even when categories aren’t predefined. By generating embeddings for each item and applying clustering techniques like k-means, you can uncover natural groupings within your data.
Conclusion
Amazon Titan Text Embeddings offers a scalable way to convert text into meaningful vectors for intelligent search, recommendations, and RAG. Multilingual support and seamless Amazon Bedrock integration enable businesses to derive deeper insights from their data and build smarter AI applications efficiently.
Drop a query if you have any questions regarding Amazon Titan Text Embeddings and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What are the limitations?
ANS: –
- 8,000 token limit per request
- Text-only (use Multimodal for images)
- Available in select AWS regions
2. Can I use it with frameworks?
ANS: – Yes, it can be integrated with LangChain, popular vector databases, and standard ML frameworks.
3. How do I optimize costs?
ANS: – Use the V2 model for better efficiency

WRITTEN BY Livi Johari
Livi Johari is a Research Associate at CloudThat with a keen interest in Data Science, Artificial Intelligence (AI), and the Internet of Things (IoT). She is passionate about building intelligent, data-driven solutions that integrate AI with connected devices to enable smarter automation and real-time decision-making. In her free time, she enjoys learning new programming languages and exploring emerging technologies to stay current with the latest innovations in AI, data analytics, and AIoT ecosystems.










Comments