

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Introduction
Building a Retrieval-Augmented Generation (RAG) system is just the first step; the next big task is to evaluate its performance. In a RAG pipeline, there are two critical steps, namely, retrieval and generation, and problems in either of these steps will impact the response generated. RAG evaluation metrics will help identify whether the documents retrieved are relevant, whether the response generated is based on the context of the documents, and whether the output is an accurate response to the question asked by the user. If you are developing an application using the RAG system or working with frameworks such as RAGAS, knowing these metrics will be very helpful.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
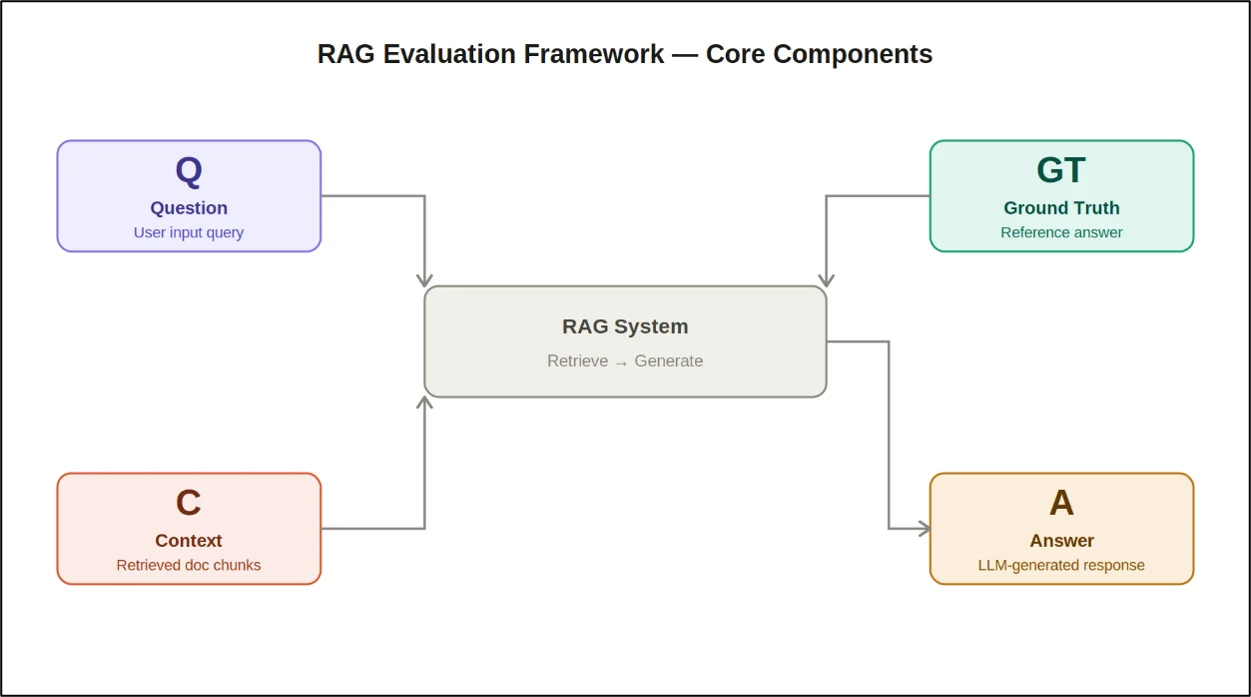
Understanding the RAG Evaluation Framework
Before exploring individual metrics, it is important to understand the four core components involved in RAG evaluation:
Metric 1: Faithfulness
What does it measure?
Faithfulness assesses whether the model’s output is grounded in facts from the context. The metric can be used to identify hallucinations that arise when an LLM produces unsubstantiated claims.
Formulation
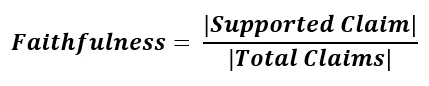
Where:
- Supported Claims = claims supported by the context
- Total Claims = all factual claims in the answer
Example
Example Context: “Python was invented by Guido van Rossum and published in 1991.” Generated Response: “Guido van Rossum invented Python in 1991. It is the most widely used programming language in the world.” Facts: Guido van Rossum invented Python (Supported Claim) Guido van Rossum published Python in 1991 (Supported Claim). Python is the most widely used programming language in the world (Non-Supported Claim). Hence,
Context: “Python was invented by Guido van Rossum and published in 1991.”
Generated Response: “Guido van Rossum invented Python in 1991. It is the most widely used programming language in the world.”
Facts:
- Guido van Rossum invented Python (Supported Claim)
- Guido van Rossum published Python in 1991 (Supported Claim)
- Python is the most widely used programming language in the world (Non-Supported Claim)
The generated answer contains 3 claims, out of which 2 claims are supported by the retrieved context and 1 claim is unsupported. Then:
![]()
Metric 2: Answer Relevancy
What does it measure?
Answer relevancy measures how well the generated answer addresses the original question. Even if an answer is perfectly faithful to the context, it might answer a slightly different question or be verbose with tangential information. These metric catches that.
Formulation
- The answer is used to generate hypothetical questions (using an LLM).
- The cosine similarity between each generated question and the original question is computed.
- The mean similarity across all generated questions is the relevancy score.
![]()
Where:
- q_i = the hypothetical question generated from the answer
- q_original = the original user question
- cosine_similarity is computed using sentence embeddings
Why This Works
The idea is simple: if the generated answer truly addresses the original question, then questions generated from that answer should closely match the user’s query. If the answer is off topic, the similarity score becomes lower.
Example
Original question: “What are the side effects of ibuprofen?”
If the answer focuses on ibuprofen dosage rather than side effects, the reverse-generated questions might look like: “What is the recommended dose of ibuprofen?” This has low similarity to the original.
![]()
Metric 3: Context Precision
What It Measures
Context Precision is an evaluation metric for determining the usefulness of the chunks that you have retrieved. In layman’s terms, it tests whether the retrieved chunks contain relevant information to the user’s question.
The greater the number of irrelevant chunks in your retriever’s response, the lower the Context Precision value will be.
Formulation
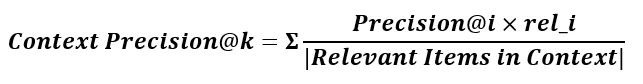
Where:
- k = total number of retrieved chunks
- Precision@i = (number of relevant items in top – i) / i
- rel_i = 1 if the i th chunk is relevant, 0 otherwise
Example
Suppose 5 chunks are retrieved. Their relevance labels (1 = relevant, 0 = not relevant) are: [1,0,1,0,1]
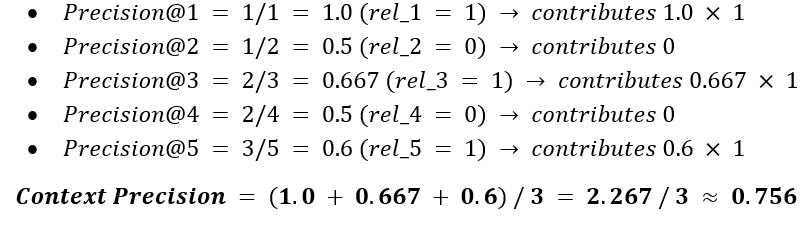
Why Rank Matters
Relevant chunks ranked higher contribute more to the score. In the case where the same documents are fetched, ranking the important chunks first results in higher Context Precision and better response quality from the RAG system.
Metric 4: Context Recall
What It Measures
Context Recall measures whether the retriever fetched all the important information needed to answer the question. While Context Precision focuses on relevance, Context Recall focuses on completeness.
A high recall score indicates that the retrieved context contains most of the information needed to generate the correct answer.
Formulation
Context Recall works by comparing the ground truth answer against the retrieved context:

Each sentence in the ground truth answer is checked to see if it can be attributed to at least one chunk in the retrieved context.
Example
Suppose 3 out of 4 ground truth sentences are found in the retrieved context.
So: Context Recall = 3/4 = 0.75
This means the retriever captured 75% of the required information.
Trade-off Between Precision and Recall
Context Precision and Context Recall usually work in balance with each other:
- Retrieving more chunks may improve recall, but can reduce precision
- Retrieving fewer chunks may improve precision but risk missing important information
Choosing the right top-k value is important for maintaining this balance.
How to Use These Metrics Together
- Scenario 1: High Faithfulness, Low Answer Relevancy → The answer is grounded in context, but the context itself is off-topic. Fix your retriever.
- Scenario 2: High Context Recall, Low Context Precision → You are retrieving too many chunks. Reduce top-k or improve re-ranking.
- Scenario 3: High Context Precision, Low Context Recall → Your retrieved chunks are relevant but incomplete. Increase top-k or improve chunking strategy.
- Scenario 4: Low Faithfulness, High Context Precision → The retriever is doing its job. The LLM is hallucinating. Fix your prompt or generation parameters.
- Scenario 5: Low Answer Correctness, High Faithfulness → The answer is grounded, but the retrieved context is missing critical information (low recall).
Conclusion
Evaluating a RAG model is crucial to determine the effectiveness of the model’s performance in terms of retrieval and generation. For example, metrics like Faithfulness, Answer Relevancy, Context Precision, and Context Recall can be used to evaluate various stages of the model.
Drop a query if you have any questions regarding RAG model, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Are all evaluation metrics used for RAG dependent on ground truth answers?
ANS: – No, some metrics, like Faithfulness and Answer Relevancy, do not require ground truth answers, whereas Context Recall requires reference answers.
2. What is the distinction between Context Precision and Context Recall?
ANS: – Context Precision indicates how relevant the chunks are, while Context Recall checks whether all the necessary information has been retrieved to respond to the question.
3. How many chunks should be retrieved within a RAG?
ANS: – Typically, the number of retrieved chunks ranges from 3 to 5. Depending on Context Precision and Context Recall, you can change the number.

WRITTEN BY Aniket Bembale
Aniket Bembale is Senior Research Associate – Data & AIoT at CloudThat, focusing on Generative AI, Agentic AI solutions and Cloud Computing. He is involved in building scalable AI-driven applications and implementing modern data and AI technologies to solve real-world business challenges.











Comments