

 Login
Login

 December 5, 2025
December 5, 2025|
Voiced by Amazon Polly |
Introduction
Applications today handle unprecedented amounts of traffic, transactions, and data. When retail sites run promotions, they receive massive traffic spikes. Banks need to process updates instantly with no delays. Travel applications constantly manage thousands of bookings that occur simultaneously. The problem is that conventional databases struggle to maintain consistent performance as volumes like these continue to scale, regardless of how much additional computing power is allocated to them.
Amazon Aurora Limitless Database addresses this problem by leveraging Amazon Aurora PostgreSQL to surpass the capabilities of a single cluster. Instead of everything running in one place, it spreads your workloads and data across several clusters that work seamlessly together. The best part is your application connects to just one endpoint-it has no idea the database is distributed. This means your team can achieve higher speeds and maintain steady performance without modifying your existing code or rewriting any SQL queries.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
How Amazon Aurora Limitless Database Works?
Amazon Aurora Limitless Database splits compute and storage across multiple layers to scale up without breaking how your application works.
- Query Coordinator
Your application connects to a single endpoint, the coordinator. This coordinator knows where your data resides, and it routes each query to the correct location. To your app, it appears to be one database, even though you might have several clusters handling the heavy lifting.
- Sharded Clusters
Large tables are automatically divided into smaller pieces called shards. Each shard runs on its own Aurora cluster. The system handles all the heavy lifting required to determine where shards go, and if necessary, it moves shards around while managing failovers. You don’t have to split anything yourself or add sharding logic into your code.
- Shared Storage Foundation
Every cluster depends on the Aurora storage system, which replicates your data across multiple availability zones for protection. Since this is a shared backbone, you can scale without compromising reliability or data consistency.
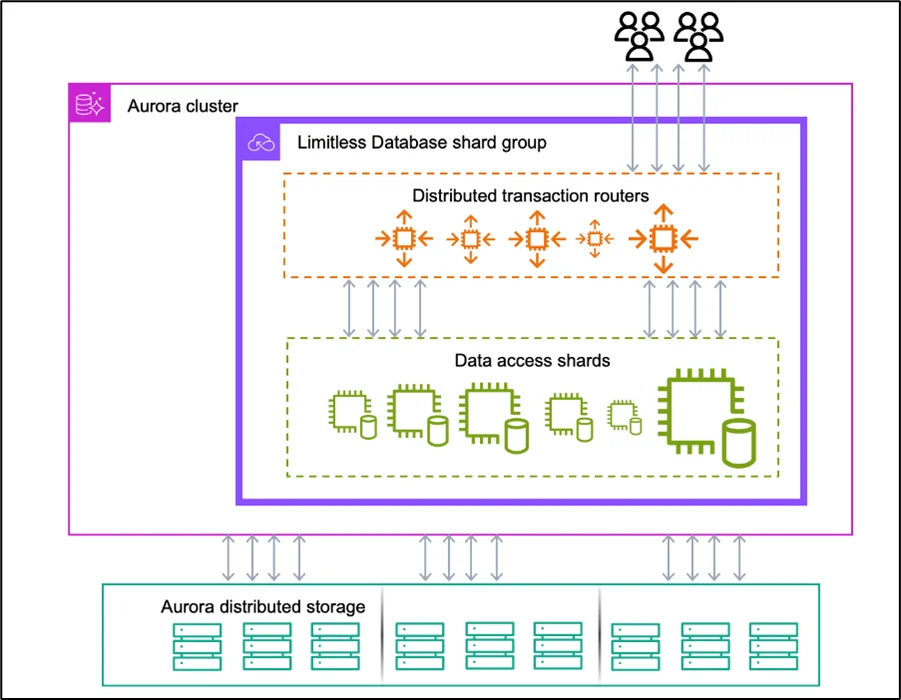
Figure 1: Source Link
Together, the pieces enable you to handle millions of writes per second while maintaining the performance and PostgreSQL compatibility of Amazon Aurora.
Why Aurora Limitless Database Matters?
Systems must be able to handle more users and transactions as companies expand. Amazon Aurora Limitless Database removes the roadblocks that normally prevent relational databases from scaling. Instead of redesigning how your data is organized, or migrating to a completely different database, your team remains with PostgreSQL, the tools and language you already use, but now has the benefits of a system that was built to scale.
It also reduces the headaches that come with scaling, as your applications don’t need new connection setup, database restructuring, or custom code to determine where data resides. Aurora handles all that automatically. The infrastructure expands as needed, providing consistent performance that you can rely on.
Ideal Use Cases
Amazon Aurora Limitless Database is suitable for applications that require continuous, low-latency writes and strict consistency at a very high scale.
- Financial Systems
Workloads such as transactions, ledger movements, and fraud detection require reliable updates at high frequency. Amazon Aurora Limitless can manage these demands while maintaining data integrity.
- E-commerce Platforms
Order management, inventory updates, and promotional events often cause large traffic spikes. Limitless Database helps keep these systems responsive and consistent during peak periods.
- Travel and Reservation Engines
Airline, hotel, and transportation systems must manage high concurrency and real-time updates. Amazon Aurora’s distributed architecture ensures that booking operations remain smooth even when demand surges.
- Gaming Applications
Player activity, matchmaking, and leaderboard updates generate continuous writes. The ability to scale horizontally ensures a stable user experience during global traffic peaks.
- SaaS Platforms
Multi-tenant applications benefit from sharding distribution, allowing for efficient isolation and predictable performance across multiple tenants.
Operational Benefits
- Single endpoint for applications, eliminating the need for complex connection management.
- Automatic data distribution eliminates manual sharding and reduces operational overhead.
- Predictable performance, whether data volumes increase or usage patterns change.
- Horizontal write scalability to enable applications to grow without architectural redesign.
- Integration with Amazon Aurora PostgreSQL, ensuring compatibility with existing SQL queries and tools.
- Fully managed service that inherits its durability, backups, and monitoring from Aurora.
Things to Consider
Amazon Aurora Limitless Database performs best when your tables are well-designed, and you have chosen suitable partitioning keys. While the system handles sharding for you, you still must choose primary keys that work to distribute your data across shards evenly. Note that your queries jumping across multiple shards may achieve different performance from queries hitting just one shard. To achieve the highest throughput, try to channel your heavy write traffic into specific shards rather than spreading it across all shards.
You’ll also want to test thoroughly before putting critical workloads into production. Since your data is spread across multiple clusters, it’s worth taking time upfront to understand your query patterns and how data flows through the system.
Security and Reliability
Amazon Aurora Limitless Database builds on Aurora’s security features. Your data is encrypted both when it is at rest and when it’s in motion. AWS IAM allows you to control exactly who has access, can modify, or manage the database. Data is kept safe across multiple availability zones within the shared storage, and every shard receives automatic backups, automatic failover in the event of an issue, and continuous monitoring. Because everything is distributed, your workloads continue to run even when one cluster goes down.
Conclusion
Amazon Aurora Limitless Database is a huge leap in how relational databases can scale. It takes the comfortable, familiar PostgreSQL interface you already know and pairs it with a distributed system capable of handling massive amounts of traffic.
For companies running mission-critical systems in finance, retail, travel, gaming, or serving a large customer base, Amazon Aurora Limitless Database provides a robust and efficient way to grow without sacrificing speed or stability.
Drop a query if you have any questions regarding Amazon Aurora Limitless Database and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is Amazon Aurora Limitless Database?
ANS: – Amazon Aurora Limitless Database is an extension of Aurora PostgreSQL that distributes workloads across multiple clusters, allowing applications to achieve massive scale while still interacting through a single endpoint.
2. How does Amazon Aurora Limitless Database scale beyond a single cluster?
ANS: – It uses a distributed architecture with query coordinators and sharded clusters. Large tables are automatically split into shards, each hosted on its own Aurora cluster, enabling millions of writes per second.
3. Do I need to change my application code to use it?
ANS: – No. Your application connects to one endpoint and doesn’t need custom sharding logic or query rewrites. Amazon Aurora handles routing, storage distribution, and scaling automatically.

WRITTEN BY Sujay Adityan
Sujay works as a Research Associate in the Data & AIoT team at CloudThat, with a background in Data Science. He is skilled in data analytics, machine learning, cloud computing, Python programming, and working with large-scale databases and networks. Sujay has contributed to multiple AI/ML and Generative AI projects for both internal teams and clients. Passionate about continuous learning, he aspires to become a proficient software developer, creating meaningful, technology-driven solutions that make a real impact.











Comments