

 Login
Login

 November 27, 2025
November 27, 2025|
Voiced by Amazon Polly |
Introduction
In today’s world, modern applications constantly generate massive amounts of real-time data from online transactions, IoT device metrics, user activity logs, and microservice communications. Handling these continuous streams of data efficiently requires a scalable, and reliable platform for real-time data processing.
Apache Kafka has emerged as the industry standard for building such data streaming pipelines. It enables distributed systems to exchange information asynchronously, handle millions of events per second, and maintain low latency, making it ideal for event-driven architectures and data analytics systems.
However, deploying and managing Kafka manually can be a challenging task. Traditional Kafka setups rely on ZooKeeper for cluster coordination and metadata management, which introduces additional complexity during scaling, upgrades, or failover scenarios.
With the rise of Kubernetes, it has become much easier to run Kafka as a containerised, self-healing, and highly available service. The Strimzi Operator, an open-source Kubernetes operator for Kafka, simplifies cluster management by automating deployment, scaling, monitoring, and upgrades through declarative Kubernetes manifests.
In this blog, we’ll explore:
- The fundamentals of Kafka and its core components,
- The shift from ZooKeeper-based architecture to KRaft mode,
- And finally, a hands-on guide to deploying Kafka on Kubernetes using the Strimzi Operator.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Apache Kafka
Apache Kafka is a distributed event streaming platform designed for high-throughput, fault-tolerant, and low-latency data pipelines. It enables producers to publish events to specific topics, and consumers to subscribe to and process these events in real-time.
Kafka acts as the central nervous system for data within an organisation, connecting applications, databases, and services in a seamless, event-driven ecosystem.
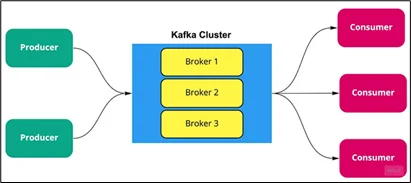
Let’s break down Kafka’s core components in simple terms:
- Producer:
An application that sends (publishes) messages to Kafka topics. Producers handle batching, serialisation, and partitioning of data for optimal throughput. - Consumer:
An application that reads (subscribes) messages from Kafka topics. Consumers typically belong to a consumer group, allowing load-balanced message consumption. - Broker:
A Kafka server that stores and manages data. Brokers handle requests from producers and consumers and replicate partitions for fault tolerance. A Kafka cluster usually consists of multiple brokers. - Topic:
A logical channel that holds streams of records. Producers write messages to topics, and consumers read from them. Topics are divided into partitions for scalability. - Partition:
A subset of a topic that stores ordered messages. Partitions enable parallel processing and can be replicated across brokers for reliability.
Together, these components form a powerful distributed messaging system that supports massive data throughput while maintaining ordering, durability, and fault tolerance.
From ZooKeeper to KRaft: Kafka’s Architectural Evolution
- ZooKeeper in Traditional Kafka
Historically, Kafka used Apache ZooKeeper for managing metadata and coordinating cluster activities. ZooKeeper was responsible for:
- Managing broker and topic metadata,
- Handling controller elections,
- Synchronizing cluster configurations,
- Detecting node failures.
Although effective, ZooKeeper introduced several challenges for large-scale Kafka operations:
- It required a separate, highly available ZooKeeper ensemble.
- Failovers could be slower due to ZooKeeper’s consensus mechanism.
- Keeping ZooKeeper and Kafka metadata in sync sometimes caused delays or inconsistencies.
As Kafka adoption grew in enterprise environments, these operational limitations led to the need for a more streamlined, self-contained architecture.
- Introducing KRaft Mode (Kafka Raft Metadata Mode)
Starting with Kafka 4.x, the project introduced a new internal consensus mechanism called KRaft (Kafka Raft), effectively removing the dependency on ZooKeeper.
KRaft integrates the Raft consensus algorithm directly into Kafka, enabling brokers to manage cluster metadata internally.
In KRaft mode:
- Brokers can serve dual roles as controllers (metadata managers) and brokers (data handlers).
- Metadata is stored within Kafka itself rather than in ZooKeeper.
- The Raft algorithm ensures consistent metadata replication and faster controller elections.
This evolution simplifies deployment, improves reliability, and enhances performance by consolidating all cluster operations under Kafka’s control.
Kafka on Kubernetes with the Strimzi Operator
Why Deploy Kafka on Kubernetes?
Running Kafka on Kubernetes brings multiple advantages for DevOps teams:
- Automation: Pods are automatically restarted, rescheduled, or replaced in case of failure.
- Declarative Management: All configurations and resources are defined in YAML manifests.
- Scalability: Easily scale Kafka brokers and consumers horizontally.
- Resource Management: Control CPU, memory, and storage per broker.
- Native Integration: Seamlessly integrate with Kubernetes monitoring, secrets, and RBAC.
However, Kafka’s distributed nature still requires orchestration. This is where Strimzi adds immense value.
Strimzi
Strimzi is an open-source Kubernetes Operator purpose-built to simplify the deployment and management of Apache Kafka.
It introduces a set of Custom Resource Definitions (CRDs) that allow you to manage Kafka clusters as native Kubernetes objects.
Key CRDs include:
- Kafka: Defines the cluster configuration, version, listeners, and storage settings.
- KafkaNodePool: Specifies broker nodes, roles (controller/broker), and replicas.
- KafkaTopic / KafkaUser: Manages topics and access controls.
- KafkaConnect / KafkaMirrorMaker2: Used for data integration and replication.
Strimzi Operator Capabilities:
- Automated cluster provisioning and scaling.
- Rolling updates and version management.
- TLS certificate and authentication management.
- Topic and user management through the Entity Operator.
- Integration with Prometheus and Grafana for monitoring.
KRaft-Based Kafka Deployment Using Strimzi
Now that we understand Kafka’s evolution and the benefits of KRaft mode, let’s walk through the steps to deploy a single-node Kafka cluster on Kubernetes using Strimzi.
Strimzi handles the entire Kafka lifecycle, including installation, configuration, scaling, upgrades, and monitoring, using Kubernetes-native resources.
Step 1: Create a Namespace for Kafka
Create a dedicated namespace to organise all Kafka-related resources.
|
1 |
# kubectl create namespace kafka |
Step 2: Install the Strimzi Operator
Install the Strimzi Operator in the kafka namespace. This operator automates the creation and management of Kafka clusters.
|
1 |
# kubectl create -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka |
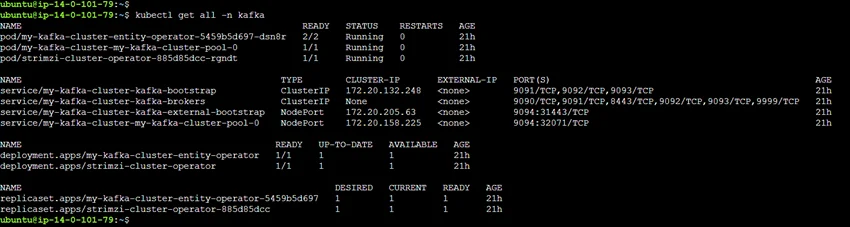
Step 3: Verify Operator Deployment
Ensure that the operator is running correctly:
|
1 |
# kubectl get all -n kafka |
Check logs for confirmation that the operator is active and error-free:
|
1 |
# kubectl logs deployment/strimzi-cluster-operator -n kafka |

Step 4: Deploy Kafka Cluster in KRaft Mode
With the operator running, deploy the Kafka cluster using Strimzi’s sample KRaft configuration file.
|
1 |
# kubectl apply -f https://strimzi.io/examples/latest/kafka/kraft/kafka-single-node.yaml -n kafka |
This configuration sets up:
- A Kafka broker running in KRaft mode (without ZooKeeper),
- The necessary services (Bootstrap and Broker),
- Persistent volume storage for Kafka data.
Step 5: Validate the Kafka Cluster
After a few minutes, check if all components are running successfully:
|
1 |
# kubectl get kafka -n kafka |

Conclusion
Deploying Apache Kafka with the Strimzi Operator on Kubernetes simplifies the entire management process for DevOps teams. By leveraging KRaft mode, Kafka eliminates its dependency on ZooKeeper, reducing operational complexity while improving scalability and reliability.
Drop a query if you have any questions regarding Apache Kafka and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is the main difference between KRaft mode and ZooKeeper in Kafka?
ANS: – KRaft mode eliminates the need for ZooKeeper by managing metadata and controller elections internally using the Raft consensus algorithm, thereby simplifying operations and enhancing performance.
2. Why use the Strimzi Operator instead of deploying Kafka manually?
ANS: – Strimzi automates Kafka deployment, scaling, and upgrades using Kubernetes CRDs, reducing manual effort and ensuring consistent, reliable cluster management.
3. Can we run Kafka in production with a single-node KRaft setup?
ANS: – A single-node setup suits testing or development; for production, a multi-node Kafka cluster is recommended for high availability and fault tolerance.

WRITTEN BY Sidda Sonali
Sidda Sonali is a Research Associate at CloudThat with a strong passion for DevOps and cloud-native technologies. She is committed to mastering modern DevOps practices and staying abreast of the latest advancements in cloud services. Sonali has hands-on experience with tools such as Terraform, Amazon EKS, Kubernetes, and Docker, and is proficient in implementing CI/CD pipelines, managing Infrastructure as Code (IaC), and automating cloud deployments. Her expertise extends to container orchestration, deployment automation, and building secure, scalable infrastructures across diverse cloud environments.











Comments