

 Login
Login
 September 5, 2025
September 5, 2025|
Voiced by Amazon Polly |
Introduction
Gemma 3n is not just a smaller LLM, it is built specifically for the real-world constraints of devices that do not have strong GPUs or constant connectivity. With edge computing in mind, Google designed this model to ensure that businesses and individual developers can deploy powerful AI capabilities in fully offline environments or low-bandwidth settings.
Gemma 3n comes in different variants such as E2B-IT and E4B-IT, where the “E” stands for Effective parameters and “IT” indicates Instruction Tuned. The E2B-IT model uses around 1.9 billion effective parameters, making it ideal for lightweight on-device applications. The E4B-IT variant contains more capacity (around 3.7–4 billion effective parameters) for higher-quality output and multimodal reasoning. Due to its MatFormer architecture, the larger E4B model actually contains the E2B model inside, allowing dynamic parameter scaling per device requirements.
This model accepts three types of input: text, audio, and images. It features a MobileNet-V5 vision encoder and a 32K token context window, and it can operate with as few as 1.9 billion active parameters while offering support for more than 140 languages. With open weights, flexible parameter activation, and support for global multilingual tasks, Gemma 3n is ideal for on-device AI such as text generation, speech recognition, image captioning, multilingual chatbots, and more.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
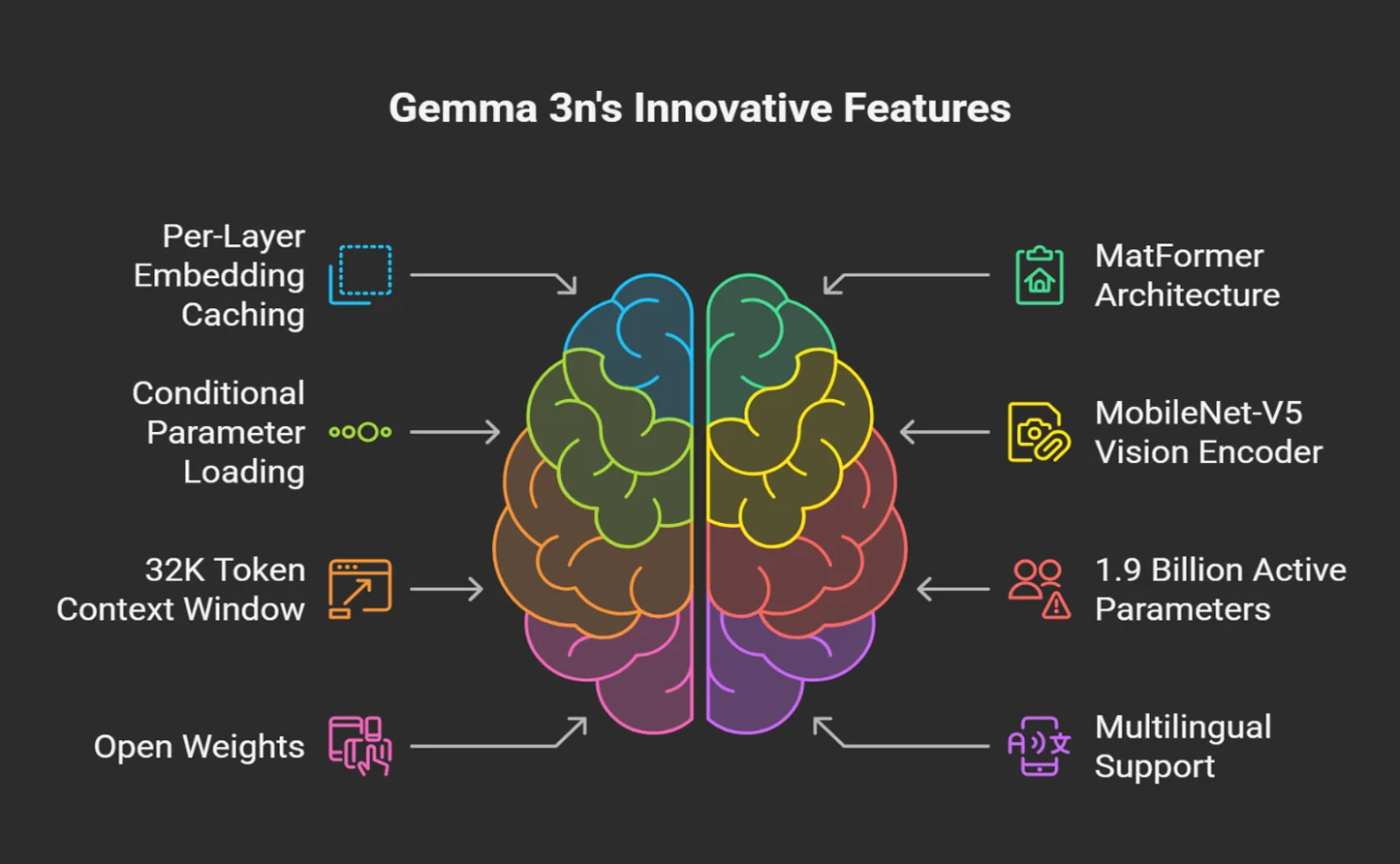
Key Features
- Multimodal Support- Gemma 3n is built to process text, audio, and visual input. This makes it suitable for complex tasks such as voice command assistants, image captioning, and multimodal chat applications, running on-device without full dependency on cloud services.
- Audio Input Processing- The model can ingest and understand raw audio data for tasks like speech-to-text, translation, or audio segment classification. This allows for real-time audio-based features on phones and laptops without external APIs.
- PLE Caching (Per-Layer Embedding) – PLE parameters are generated and cached separately, helping reduce the memory footprint during runtime. This allows Gemma 3n to produce high-quality outputs while consuming less RAM by offloading certain parameters to faster local storage.
- MatFormer Architecture – Gemma 3n uses a Matryoshka Transformer architecture that nests smaller sub-models within a larger model. This lets developers selectively activate only the parameters needed for a specific task, reducing compute cost and latency. For example, the E4B model contains the E2B model inside it and can run with minimal resources if required.
- Conditional Parameter Loading – You can skip loading vision or audio-related weights when they aren’t needed, which makes the model even lighter. This is especially useful for low-power devices that only need basic text generation capabilities.
- Wide Language Support – Gemma 3n is trained on over 140 languages, allowing it to power multilingual chatbots, localization features, and globally scalable applications without needing different models for each language.
- 32K Token Context Window – With a context window of 32,000 tokens, Gemma 3n can handle long conversations, large documents, or detailed instruction prompts without truncation. This makes content summarization, code understanding, or document analysis use cases valuable.
Text Generation Example
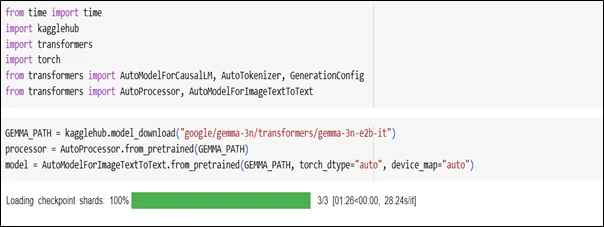
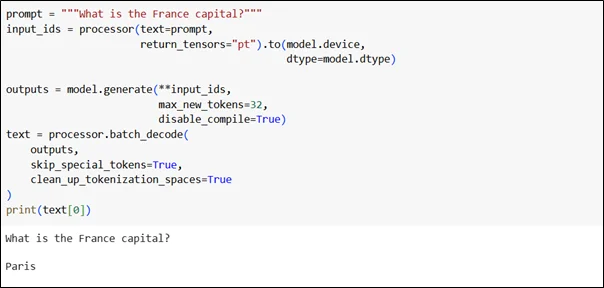
Use Cases
- Voice Assistants and Smart Speakers – With its audio input capabilities, Gemma 3n can power offline or on-device voice assistants that perform speech recognition and natural language understanding without constant internet access, enhancing privacy and reducing latency.
- Multimodal Mobile Applications – Developers can build mobile apps that combine text, images, and audio in a single interaction. For example, a travel app could let users speak a query, analyze a photo, and generate a text-based response locally.
- Personal AI Companions – Because of its lightweight deployment, Gemma 3n can run offline personal chatbots or journaling assistants that maintain user privacy and respond in natural language.
- Edge AI for IoT Devices – The model can be embedded in smart home devices, wearables, or industrial sensors, enabling on-site intelligence such as predictive maintenance or contextual alerts based on audio or textual signals.
- Education and Learning Tools – Gemma 3n can personalize educational content, summarize lessons, or generate quizzes tailored to the user’s progress, even in areas with limited internet.
- Multilingual Customer Support Bots –With support for over 140 languages, it can be used to deploy chatbots that handle help requests in multiple languages directly in apps, reducing the need for multiple models and translation tools.
Conclusion
Gemma 3n enables generative AI to run on everyday devices by blending efficiency with multimodal features. Features like PLE caching, MatFormer architecture, and conditional parameter loading allow developers to build intelligent, responsive applications that run anywhere. Whether generating text, processing audio, or analyzing images, Gemma 3n makes cutting-edge AI more accessible and deployable across various use cases.
Drop a query if you have any questions regarding Gemma and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Does Gemma 3n require internet connectivity?
ANS: – No, it is optimized for on-device usage so that many tasks can run fully offline.
2. Can I skip loading audio or vision parameters?
ANS: – Yes, you can load only text parameters to reduce memory usage and improve performance on low-resource devices.
3. Is Gemma 3n open-source?
ANS: – Yes, it is provided with open weights and licensed for responsible commercial use.

WRITTEN BY Livi Johari
Livi Johari is a Research Associate at CloudThat with a keen interest in Data Science, Artificial Intelligence (AI), and the Internet of Things (IoT). She is passionate about building intelligent, data-driven solutions that integrate AI with connected devices to enable smarter automation and real-time decision-making. In her free time, she enjoys learning new programming languages and exploring emerging technologies to stay current with the latest innovations in AI, data analytics, and AIoT ecosystems.











Comments