

 Login
Login

 September 22, 2025
September 22, 2025|
Voiced by Amazon Polly |
Overview
Modern Retrieval-Augmented Generation (RAG) applications rely on vector embeddings to retrieve relevant information from large datasets. Amazon S3 Vectors is a cost‐optimized object storage service that natively supports storing and querying high-dimensional vectors. Combining S3 Vectors with Amazon Bedrock Knowledge Bases gives you a fully managed RAG workflow that dramatically cuts costs while preserving sub-second retrieval performance. For example, S3 Vectors can reduce vector storage and query costs by up to 90% compared to SSD-based vector databases.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Prerequisites
- AWS Account: Ensure Amazon Bedrock is enabled, and you have AWS IAM access to Amazon Bedrock and Amazon S3 Vectors.
- AWS IAM Role/Permissions: You will need an AWS IAM role (or user) with permissions for S3 Vectors (s3vectors:CreateVectorBucket, s3vectors:CreateIndex, s3vectors:PutVectors, s3vectors:QueryVectors, etc.) and Amazon Bedrock Knowledge Bases. If you encrypt your vector bucket with a customer-managed AWS KMS key, also include AWS KMS permissions. Example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "Statement": [ { "Effect": "Allow", "Action": [ "s3vectors:*", "s3:GetObject", "s3:PutObject", "bedrockagent:*", "bedrockdata:*", "kms:*" ], "Resource": "*" } ] } |
- Embedding Model Access: Bedrock supports Amazon Titan and other embedding models. For text data, Amazon Titan Text Embedding v2 is a good choice (outputs 1,024-dim vectors by default). Depending on your use case, you can also use Cohere’s embedding models or image embeddings.
- AWS CLI / SDK: Install AWS CLI v2 and configure it, or use Boto3 (Python). Use the latest version that supports Amazon S3 Vectors and Amazon Bedrock commands.
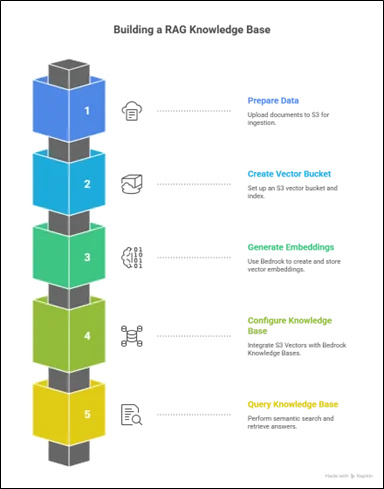
Step-by-Step Guide
Step 1: Prepare and Ingest Source Data into Amazon S3
First, upload your documents to a standard Amazon S3 bucket. This is the data source for your knowledge base. For example:
|
1 |
aws s3 cp ./my-manuals/ s3://my-doc-bucket/manuals/ --recursive |
Once uploaded, Amazon Bedrock can ingest these files, chunk them, and generate embeddings.
Step 2: Create an Amazon S3 Vector Bucket and Index
# Create a new Amazon S3 vector bucket
|
1 2 3 |
aws s3vectors create-vector-bucket \ --vector-bucket-name my-vector-bucket \ --region us-east-1 |
# Create a vector index
|
1 2 3 4 5 6 7 |
aws s3vectors create-index \ --vector-bucket-name my-vector-bucket \ --index-name my-vector-index \ --data-type float32 \ --dimension 1024 \ --distance-metric cosine \ --region us-east-1 |
Python example:
|
1 2 3 4 5 6 7 8 9 10 11 |
import boto3 s3vectors = boto3.client('s3vectors', region_name='us-east-1') s3vectors.create_vector_bucket(VectorBucketName='my-vector-bucket') s3vectors.create_index( VectorBucketName='my-vector-bucket', IndexName='my-vector-index', DataType='float32', Dimension=1024, DistanceMetric='COSINE' ) |
Step 3: Generate and Store Vector Embeddings
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import boto3, json s3 = boto3.client('s3', region_name='us-east-1') bedrock = boto3.client('bedrock-runtime', region_name='us-east-1') s3vectors = boto3.client('s3vectors', region_name='us-east-1') # Load document bucket_name = 'my-doc-bucket' object_key = 'manuals/chapter1.txt' text = s3.get_object(Bucket=bucket_name, Key=object_key)['Body'].read().decode('utf-8') # Generate embedding response = bedrock.invoke_model( modelId='amazon.titan-embed-text-v2:0', contentType='application/json', body=json.dumps({"text": text}) ) embeddings = json.loads(response['body'].read())['embeddings'] # Store in S3 Vector index vectors = [{ 'key': 'manuals/chapter1', 'data': {'float32': embeddings}, 'metadata': {'source': f's3://{bucket_name}/{object_key}'} }] s3vectors.put_vectors( vectorBucketName='my-vector-bucket', indexName='my-vector-index', vectors=vectors ) |
Step 4: Create and Configure the Amazon Bedrock Knowledge Base
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
aws bedrock create-knowledge-base \ --name "MyS3VectorKB" \ --description "Knowledge base using S3 vector store" \ --role-arn arn:aws:iam::123456789012:role/MyBedrockServiceRole \ --knowledge-base-configuration '{ "vectorStore": { "type": "S3_VECTORS", "s3VectorsConfiguration": { "vectorBucketArn": "arn:aws:s3:::my-vector-bucket", "indexArn": "arn:aws:s3vectors:us-east-1:123456789012:vectorIndex/my-vector-index", "indexName": "my-vector-index" } }, "embeddingModelArn": "arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-embed-text-v2:0" }' |
Python example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
bedrock_agent = boto3.client('bedrock-agent', region_name='us-east-1') response = bedrock_agent.create_knowledge_base( name='MyS3VectorKB', description='KB with S3 Vectors', roleArn='arn:aws:iam::123456789012:role/MyBedrockServiceRole', knowledgeBaseConfiguration={ 'vectorStore': { 'type': 'S3_VECTORS', 's3VectorsConfiguration': { 'vectorBucketArn': 'arn:aws:s3:::my-vector-bucket', 'indexArn': 'arn:aws:s3vectors:us-east-1:123456789012:vectorIndex/my-vector-index', 'indexName': 'my-vector-index' } }, 'embeddingModelArn': 'arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-embed-text-v2:0' } ) |
Step 5: Query the Knowledge Base (RAG Workflow)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1') response = bedrock_runtime.retrieve_and_generate( input={'text': 'What safety protocols does the manual describe?'}, retrieveAndGenerateConfiguration={ 'knowledgeBaseConfiguration': { 'knowledgeBaseId': 'your-kb-id', 'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-embed-text-v2:0' } } ) answer = json.loads(response['body'].read())['generatedText'] print("Answer:", answer) |
Use Cases
- Chatbots: Build customer or employee support bots that ground responses in your company data.
- Document Q&A: Query manuals, policies, or knowledge repositories with natural language.
- Research Assistants: Summarize and extract key points from large document collections.
Conclusion
Developers can create scalable and cost-efficient RAG solutions by combining Amazon S3 Vectors with Amazon Bedrock Knowledge Bases. The workflow is straightforward: ingest data into Amazon S3, build embeddings with Bedrock, store vectors in Amazon S3 Vector Buckets, and enable semantic search with Bedrock Knowledge Bases. This setup powers accurate, explainable, cost-effective AI-driven applications like chatbots and document search engines.
Drop a query if you have any questions regarding Amazon Bedrock and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What embedding dimension should I choose when creating the vector index?
ANS: – The dimension must match the output size of your embedding model.
- For Titan Text Embedding v2, use 1024.
- For other models (like Cohere embeddings), check the model’s documentation.
2. Can I store non-text data in Amazon S3 Vectors?
ANS: – Yes. Embeddings can come from text, images, or other modalities. For example, you could store image embeddings (using Titan Image Embedding) and build a semantic image search system.
3. What distance metric should I use: cosine, dot, or Euclidean?
ANS: –
- Cosine is most common for semantic similarity in NLP tasks.
- The dot product may be used in specialized cases (like normalized vectors).
- Euclidean is suitable when absolute vector distance matters.

WRITTEN BY Shantanu Singh
Shantanu Singh is a Research Associate at CloudThat with expertise in Data Analytics and Generative AI applications. Driven by a passion for technology, he has chosen data science as his career path and is committed to continuous learning. Shantanu enjoys exploring emerging technologies to enhance both his technical knowledge and interpersonal skills. His dedication to work, eagerness to embrace new advancements, and love for innovation make him a valuable asset to any team.










Comments