

 Login
Login

 January 18, 2023
January 18, 2023|
Voiced by Amazon Polly |
Overview
To make it easier to import data from Amazon S3 into Amazon Redshift, an auto-copy capability is now available in the preview on Amazon Redshift. You no longer require extra software or specialized solutions to track your Amazon S3 paths and automatically load new files when you set up continuous file ingestion rules.
Users of Amazon Redshift use COPY statements to load information from multiple data sources, including Amazon S3, into their local tables. In a Copy Job, you can now store a COPY statement, and the Copy Job will instantly load any new files it finds in the Amazon S3 path. Copy Jobs keep track of previously loaded files and don’t allow them to be ingested. The system tables can be used to keep track of their activity. When automated loading is not required, copy jobs can also be manually run to reuse copy statements and avoid data duplication.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
Demo on Continuous File Ingestion from Amazon S3
To create a cluster in Preview
- Sign in to the AWS Management Console and open the Amazon Redshift Console at https://console.aws.amazon.com/redshift/.
- Select Provisioned clusters dashboard from the navigation menu and Click Clusters.

There is a list of the clusters for your account in the current AWS Region. Each cluster’s subset of attributes is shown in a column in the list.
The following AWS Regions have access to this preview:
- US East (N. Virginia) Region (us-east-1)
- US West (Oregon) Region (us-west-2)
- Asia Pacific (Tokyo) Region (ap-northeast-1)
- Europe (Stockholm) Region (eu-north-1)
- Europe (Ireland) Region (eu-west-1)
- US East (Ohio) Region (us-east-2)
3. On the Clusters list page, a banner introducing the preview appears. To access the create cluster page, Select the Create preview cluster

4. Enter the cluster’s characteristics. The Preview track with the features you want to test should be selected. We suggest providing the cluster with a name that indicates that it is on a preview track. For the features, you want to test, select options for your cluster, including those labeled with the –preview.

Note: For creating clusters, refer to Creating a cluster in the Amazon Redshift Management Guide.
5. Click Create preview cluster to create a cluster in preview.

6. When your preview cluster is available, install a SQL client then connect your SQL client to a database in your cluster, and use your SQL client to load and query data.
7. Use COPY JOB to load data into Amazon Redshift tables from files that are stored in Amazon S3.
To see the status and progress of COPY JOB, you should query system views. Views are provided as follows:
- SYS_COPY_JOB (preview)– contains a row for each currently defined COPY JOB.
- STL_LOAD_ERRORS– contains errors from COPY commands.
- STL_LOAD_COMMITS– contains information used to troubleshoot a COPY command data load.
- SYS_LOAD_HISTORY– contains details of COPY commands.
- SYS_LOAD_ERROR_DETAIL– contains details of COPY command errors.
To get the list of files loaded by a COPY JOB, run the following example replacing <job_id>:

Conclusion
Users can transfer data from sources (Amazon S3) and store it in Amazon Redshift utilizing the auto-copy functionality, eliminating the need to create a separate data intake procedure or keep track of all imported files.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat
FAQs
1. What is Amazon Redshift?
ANS: – “Amazon Redshift is an enterprise-level, petabyte scale, fully managed data warehousing service.” – Amazon Docs
Business intelligence (BI), reporting, data, and analytics tools are just among the various types of applications that Amazon Redshift enables client connections. To get a final result, we retrieve, compare, and evaluate significant volumes of data when we perform analytical queries as shown below.
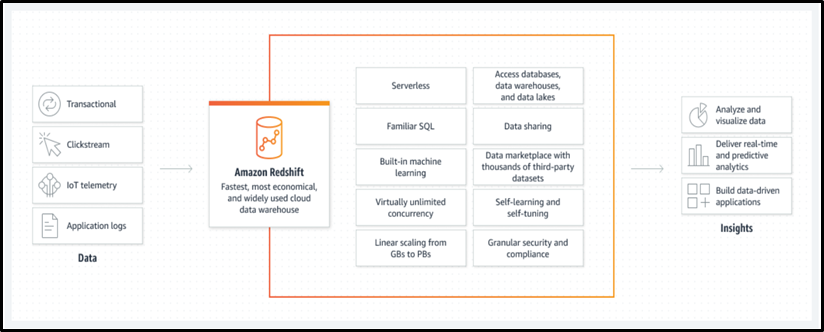 Source: AWS
With AWS-designed hardware and machine learning, Amazon Redshift employs SQL to analyze structured and semi-structured data from data warehouses, operational databases, and data lakes, providing the greatest pricing performance at any scale.
Source: AWS
With AWS-designed hardware and machine learning, Amazon Redshift employs SQL to analyze structured and semi-structured data from data warehouses, operational databases, and data lakes, providing the greatest pricing performance at any scale.
2. What is Amazon S3?
ANS: – A service for object storage is Amazon Simple Storage Service (Amazon S3). For a variety of use cases, including data lakes, websites, mobile applications, backup and restore, archives, business applications, IoT devices, and big data analytics, use Amazon S3 to store and preserve any quantity of data. Amazon S3 provides management tools that let you organize, optimize, and customize access to your data to meet your specific business, organizational, and regulatory needs.
3. Will auto-copy work on production?
ANS: – No, you can create an Amazon Redshift cluster in Preview to test new features of Amazon Redshift. You cannot transfer your Preview cluster to a production cluster or a cluster on a different track, nor can you use those capabilities in production. For the terms and conditions of previews, see Beta and Previews in AWS Service Terms

WRITTEN BY Anjali Sikhwal
Anjali Sikhwal works as a Subject Matter Expert - Data and AIoT at CloudThat and holds a Master's & PGD in Data Science. She is interested in Artificial intelligence and Machine learning technologies. She helps clients to deploy robust ML models. Her hobbies are exploring new places and music.











Comments