

 Login
Login

 September 21, 2023
September 21, 2023|
Voiced by Amazon Polly |
Overview
Data is essential for a business, whether it is decision-making, understanding performance, improving processes, or understanding consumer behavior.
This is Part – 2 of the dbt series, and in this blog, let’s see how we can set up our first dbt project and use it with one of the most popular cloud warehousing platforms, ‘Snowflake’. If you want to check Part – 1 of this series, where I explained dbt and its impact on modern data stacks, please refer here.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
dbt (data build tool) is a popular open-source command-line tool for managing and orchestrating data transformation workflows. It helps data analysts and engineers work with data and build data models efficiently.
We can create reusable SQL-based ‘models’ that define how your data should be transformed and organized. Before going to dbt setup and configuration, let’s understand what dbt models are, what modularity is, and how to apply it to analytics.
Models in dbt
In analytics, ‘Modelling’ shapes data from its raw form to its final transformed form. Typically, data engineers are responsible for creating source tables to store raw data and then building views or tables that transform the raw data. These are also called ‘intermediate tables or views’. Eventually, final tables will be built for transformed data, and from there, it can be used for BI and analytics.
In dbt, ‘Models’ are simple SQL SELECT statements (CTEs) saved as SQL files with the ‘.sql’ extension. Each model in dbt has a one-to-one relationship with a table or view in our data warehouse. It means every table or view in a data warehouse and a model is associated with it in dbt. The main advantage of dbt is we don’t need to write DDL or DML to build a table or a view, we can configure these settings at the top within the SQL file, and dbt will handle the rest.
Modularity:
‘Modularity’ is building a final product individually rather than individually. We can apply modularity to our analytics logic in such a way that to build a final table by breaking all the SQL logic (CTEs) needed to build that table into separate models.
The ‘ref’ function:
- In simple terms, ref() refers to one model inside another. The ref() uses these references between models to automatically build the dependency graph, which enables dbt to deploy models in the correct order. ref() helps us maintain clean SQL logic and practices the DRY principle to avoid the repetition of the same logic elsewhere.
Data Modeling in dbt:
‘Data Modeling’ defines how data should be organized in a database and used to optimize storage costs by reducing data redundancy.
Naming conventions in dbt models:
- Sources: Sources are not models but reference raw data already loaded into a data warehouse.
- Staging models: These models are built to stage the data from underlying source tables. Each source table will have one staging model associated with it.
- Intermediate models: These models exist between staging and final models and are built on top of the staging models.
- Fact models: Contains data related to the stats. Most of the data in these models is some kind of metric like events, clicks, votes, etc.
- Dimension models: Contains data related to a person or a place. Most of the data in these models is related to users, companies, products, customers, etc.
Steps to Set up dbt project with Snowflake
For this demo, we use ‘jaffle_shop’ & ‘stripe’ CSV datasets available in the public S3 bucket. We need an active Snowflake account with ACCOUNTADMIN access and a dbt Cloud account.
- Let’s create a new virtual warehouse in Snowflake and two databases and schemas (one for ‘jaffle_shop’ data and the other for ‘stripe’ data). Refer to the Snowflake SQL script below to perform these activities.
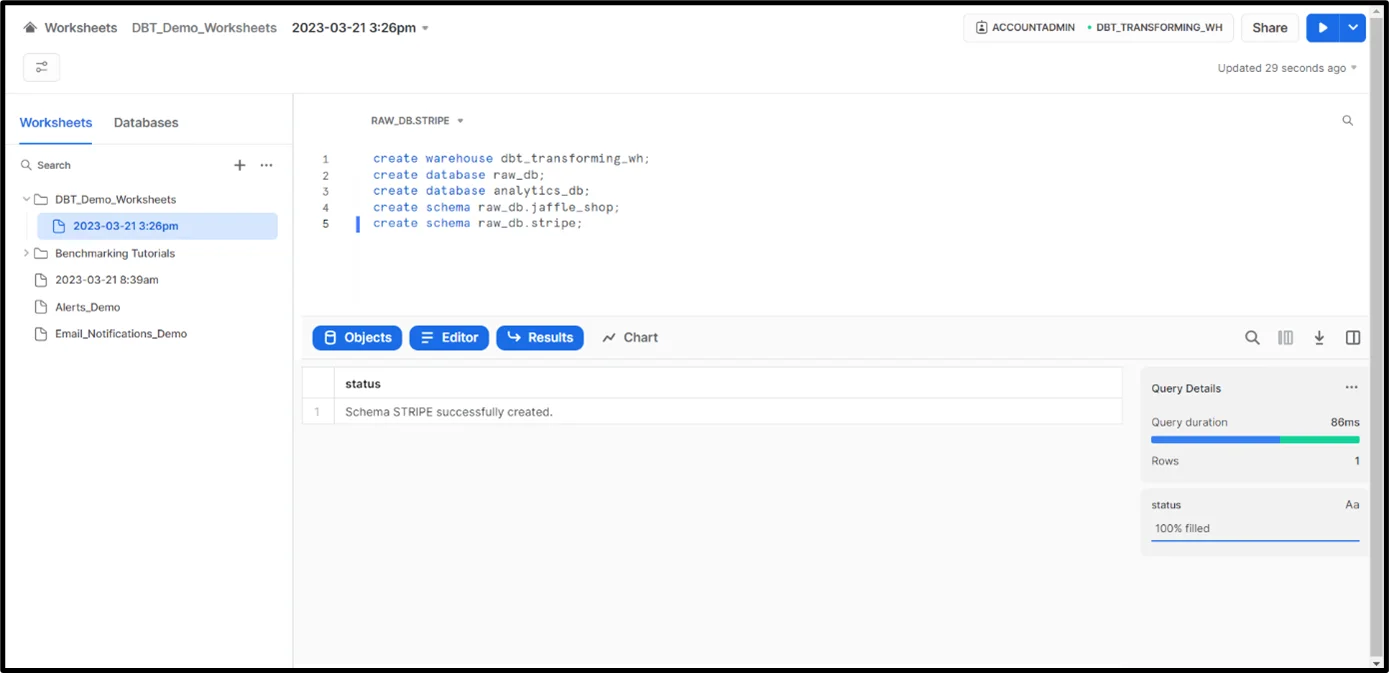
2. Create three tables in both ‘jaffle_shop’ and ‘stripe’ schemas in the ‘raw_db’ database and load the relevant data.
- The first table we must create is the ‘customer’ table.

- The second table we must create is the ‘orders’ table.

- The third table we must create is the ‘payment’ table.

3. In this step, we load the data into all the above three tables from CSV datasets available in the S3 bucket.
- Loading data into the ‘customer’ table in the ‘jaffle_shop’ schema of the ‘raw_db’ database.
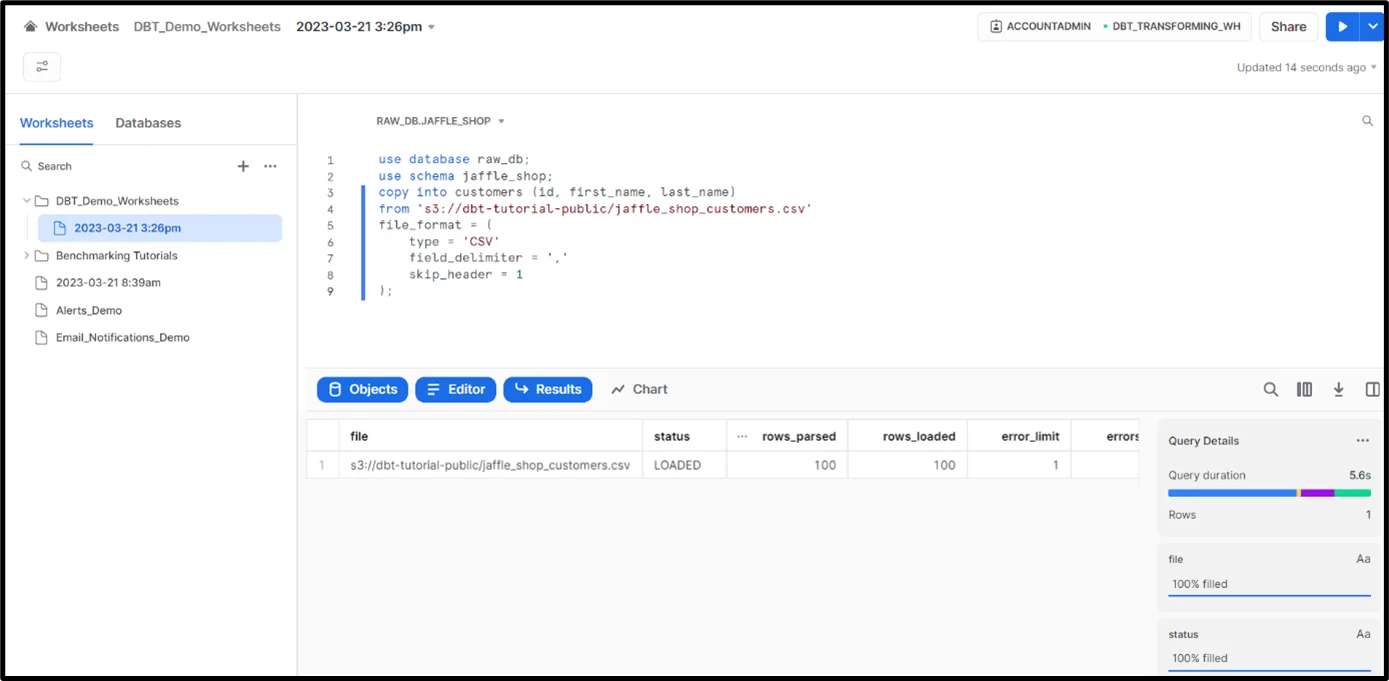
- Loading data into the ‘orders’ table in the ‘jaffle_shop’ schema of the ‘raw_db’ database.

- Loading data into the ‘payment’ table in the ‘stripe’ schema of the ‘raw_db’ database.
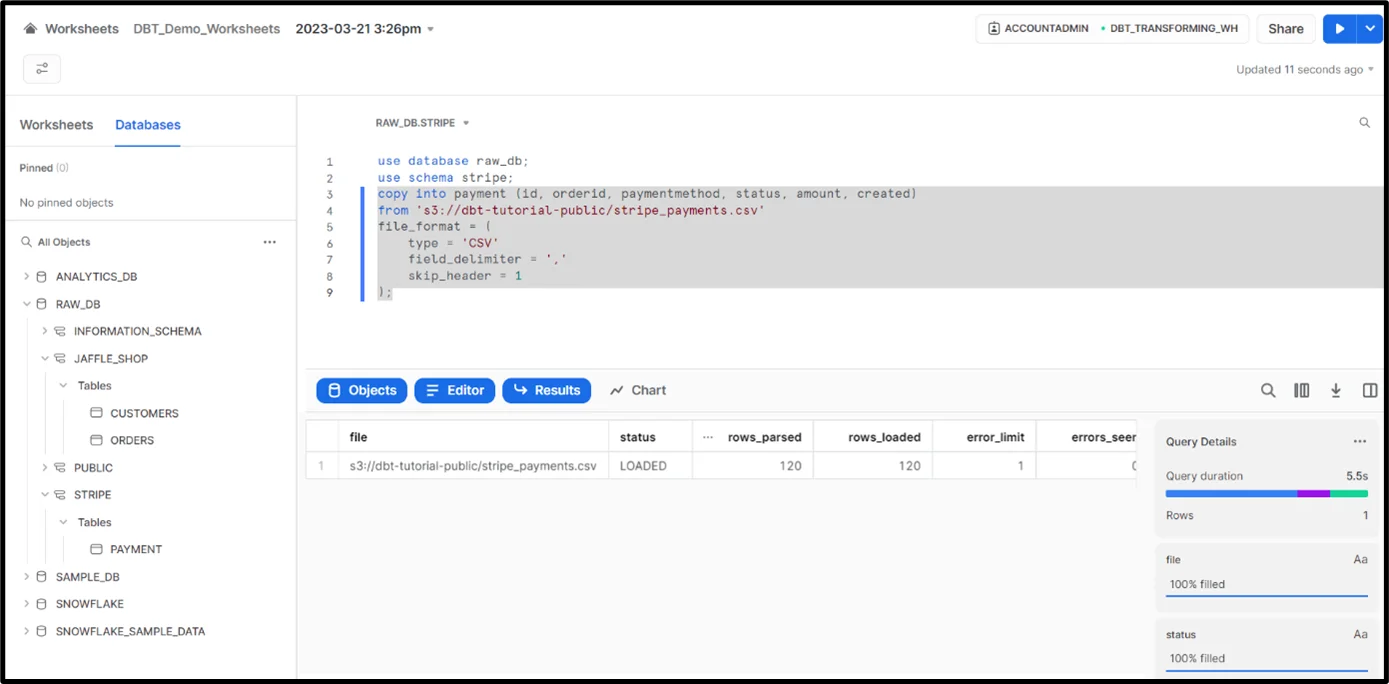
4. Verify whether data is successfully loaded or not into tables.

5. Let’s connect our Snowflake account with the dbt cloud. There are two ways to connect our dbt cloud to Snowflake. The first is partner connect available within the Snowflake, and dbt takes care of the entire setup and configuration. The second is connecting manually by creating a separate dbt cloud account, and in this, we can customize our entire setup. Let’s connect to the dbt cloud from Partner Connect for this demo.
- In the ‘Snowsight’ console, go home, click on ‘Admin’, select ‘Partner Connect’ from the list of options, and search for ‘dbt’ in Partner Connect. If we are using a classic UI console, you can directly select a partner to connect from the top pane.

- Click ‘dbt’ in the partner connects and then click ‘connect’. dbt will handle the connection and create some objects in our Snowflake account.

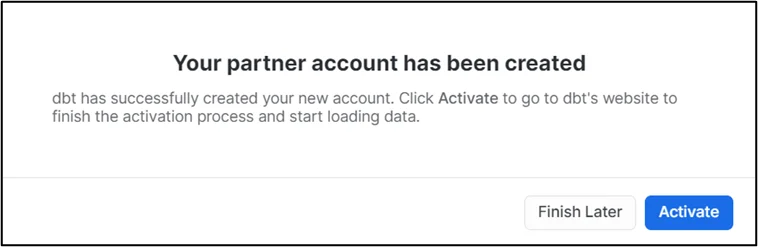
- Once your partner account has been created, click ‘Activate’ to finish the activation process and start loading data.
- Once you click activate, the control will be navigated to the dbt cloud in a new tab and prompted for credentials. Click on ‘complete registration’ to finish setting up your dbt cloud account by providing valid credentials. Once registration is completed, the dbt homepage will be opened like the picture below.

The Snowflake account is now connected to the dbt cloud environment.
Conclusion
As you can see, connecting Snowflake with dbt Cloud is straightforward. This blog has explained various insights on connecting dbt Cloud to Snowflake to help you improve decision-making when making the most of your data. In the next part of this dbt series, we will see how to initialize our dbt project and sources, build our first dbt model, change the materializations, and create dependencies.
Drop a query if you have any questions regarding Snowflake and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. How to upgrade from classic UI to Snowsight in Snowflake?
ANS: – There are two options to access Snowsight:
- To sign in to Snowsight directly, go to ‘https://app.snowflake.com’ and use your snowflake credentials.
- To sign in to Snowsight using the classic console, select Snowsight in the upper right corner of the classic console.
2. What are Downstream Models?
ANS: – While we create dependencies between models, dbt will create a DAG representing those dependencies from a source called ‘upstream models’ to staging or intermediary models up to final tables called ‘downstream models’.

WRITTEN BY Yaswanth Tippa
Yaswanth is a Data Engineer with over 4 years of experience in building scalable data pipelines, managing Azure and Databricks platforms, and leading data governance initiatives. He specializes in designing and optimizing enterprise analytics solutions, drawing on his experience supporting multiple clients across diverse industries. Passionate about knowledge sharing, Yaswanth writes about real-world challenges, architectural best practices, and lessons learned from delivering robust, data-driven products at scale.










Comments