

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Overview
Artificial Intelligence (AI) is transforming how organizations process and retrieve information. From chatbots and recommendation systems to image recognition and document search, modern applications increasingly rely on understanding the meaning behind data rather than simply matching keywords. However, traditional databases were not designed to support this type of semantic understanding efficiently.
This is where Vector Databases come into play. They provide a specialized way to store, index, and search data represented as vectors, making them a crucial component of modern AI systems. In this blog, we will explore what vector databases are, how they work, and why they have become an essential technology for AI-powered applications.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Vector Database
A vector database is a database specifically designed to store and query vector embeddings. These embeddings are numerical representations of data generated by machine learning models. They capture the meaning, context, and relationships within data and map them into a high-dimensional mathematical space.
For example, consider the following sentences:
- “I enjoy playing football.”
- “Soccer is my favorite sport.”
- “I like eating pizza.”
Although the first two sentences use different words, they express a similar idea. When converted into embeddings, they will be positioned close together in vector space. The third sentence, which discusses an entirely different topic, will be located farther away.
Unlike traditional databases that rely on exact matches, vector databases can identify data that is conceptually similar, making them ideal for semantic search and AI-driven applications.
Why Traditional Databases Are Not Sufficient?
Relational databases are excellent at handling structured data and executing exact-match queries. They can efficiently answer questions such as:
- Find all customers from a specific city.
- Retrieve orders placed in the last month.
- Fetch records with a particular identifier.
However, AI applications often require similarity-based searches rather than exact matches. For example, a recommendation engine may need to identify products that resemble a user’s interests, even if the product descriptions use different wording.
Performing such comparisons against millions of records using conventional databases can be computationally expensive and slow. As datasets grow, search latency increases significantly.
Vector databases solve this challenge by using specialized indexing and search algorithms that can quickly identify similar vectors without comparing every record individually.
Key Components of a Vector Database
- Embedding Generation
Before data can be stored in a vector database, it must be converted into vector embeddings using machine learning models.
Common embedding models include:
- OpenAI Embedding Models
- Sentence Transformers
- BERT-based Models
- CLIP for image embeddings
These models transform text, images, audio, and other forms of data into numerical vectors that capture their semantic meaning.
- Vector Storage
The generated embeddings are stored in the database along with relevant metadata.
Example:
|
1 2 3 4 5 6 |
{ "id": 101, "title": "Football Basics", "category": "Sports", "embedding": [0.21, 0.87, 0.45, ...] } |
Metadata allows users to apply filters during searches, such as retrieving documents from a specific category or time period.
- Vector Indexing
Searching billions of vectors directly would be inefficient. To accelerate retrieval, vector databases create specialized indexes.
Popular indexing techniques include:
- HNSW (Hierarchical Navigable Small World)
- IVF (Inverted File Index)
- Product Quantization (PQ)
- Annoy
- ScaNN
These indexing methods support Approximate Nearest Neighbor (ANN) search, enabling high-speed retrieval with minimal accuracy loss.
- Similarity Measurement
To determine which vectors are most relevant to a query, vector databases use similarity metrics such as:
- Cosine Similarity
- Euclidean Distance
- Dot Product
The database returns the vectors closest to the query vector, according to the selected metric.
How Vector Databases Work?
The overall workflow of a vector database is straightforward:
- Raw data is converted into embeddings using an AI model.
- The embeddings are stored and indexed within the vector database.
- A user’s query is transformed into a vector embedding.
- The database performs a similarity search against stored vectors.
- The most relevant results are returned.
For instance, if a user searches for “best practices for cloud security,” the database may retrieve documents discussing encryption, identity management, and access controls—even if those exact keywords are not present in the search query.
This ability to understand context rather than relying solely on keywords makes vector databases particularly powerful.
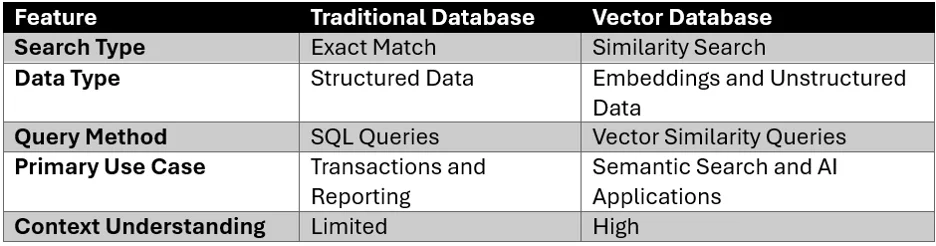
Traditional Databases vs Vector Databases
Real-World Applications
Semantic Search
Vector databases enable search engines to understand user intent and retrieve results based on meaning rather than exact keywords.
Recommendation Systems
Streaming platforms, e-commerce websites, and social networks use vector similarity to recommend content, products, and connections tailored to user preferences.
Retrieval-Augmented Generation (RAG)
RAG has become one of the most important use cases for vector databases.
In a RAG workflow:
- Documents are converted into embeddings.
- Embeddings are stored in a vector database.
- User questions are transformed into vectors.
- Relevant information is retrieved.
- A Large Language Model (LLM) generates a response using the retrieved context.
This approach improves answer quality and reduces hallucinations.
Image and Multimedia Search
Users can search for visually similar images, videos, or audio clips without relying on manually assigned tags.
Fraud Detection
Financial institutions can compare transaction patterns represented as vectors and identify unusual behavior that may indicate fraud.
Popular Vector Database Solutions
Several vector database platforms are widely adopted today:
- Pinecone
- Weaviate
- Milvus
- Qdrant
- Chroma
- Elasticsearch Vector Search
- PostgreSQL with pgvector
Each platform offers distinct strengths in scalability, deployment options, indexing strategies, and ecosystem integration.
Benefits of Vector Databases
Vector databases provide several important benefits:
- Fast similarity searches across massive datasets
- Improved semantic understanding
- Better recommendation quality
- Efficient handling of unstructured data
- Strong support for AI and machine learning workloads
- Seamless integration with Large Language Models and RAG architectures
These capabilities make them a foundational technology for intelligent applications.
Conclusion
As organizations continue to adopt AI-driven solutions, the ability to search and retrieve information based on meaning has become increasingly important. Vector databases address this need by enabling efficient storage and retrieval of embeddings, allowing applications to perform semantic search, recommendations, multimedia discovery, and contextual information retrieval.
Drop a query if you have any questions regarding the vector database, and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. Why are vector databases used?
ANS: – They enable fast similarity searches for AI applications like semantic search and recommendations.
2. What is a vector embedding?
ANS: – A vector embedding is a numerical representation of data generated by an AI/ML model.
3. Can vector databases work with LLMs?
ANS: – Yes, they are widely used in RAG architectures to provide relevant context to Large Language Models.

WRITTEN BY Sonam Kumari
Sonam is a Software Developer at CloudThat with expertise in Python, AWS, and PostgreSQL. A versatile developer, she has experience in building scalable backend systems and data-driven solutions. Skilled in designing APIs, integrating cloud services, and optimizing performance for production-ready applications, Sonam also leverages Amazon QuickSight for analytics and visualization. Passionate about learning and mentoring, she has guided interns and contributed to multiple backend projects. Outside of work, she enjoys traveling, exploring new technologies, and creating content for her Instagram page.











Comments