

 Login
Login

 May 21, 2026
May 21, 2026|
Voiced by Amazon Polly |
Introduction
There’s a moment every developer hits after building a RAG system, you run a few queries, the answers look reasonable, and you think: this is probably good enough. But “probably” is not a measurement. And “looks reasonable” is not a metric.
That gut-check approach breaks down the moment you change a prompt, swap a retriever, or scale to real users. You need something more rigorous. You need Ragas.
Ragas (short for Retrieval-Augmented Generation Assessment) is an open-source Python library that brings quantitative, repeatable evaluation to LLM and RAG systems. What makes it unusual is that it doesn’t demand a pre-labeled dataset to get started, it uses an LLM as a judge to score your pipeline’s outputs across multiple quality dimensions. Ship faster, measure honestly, and stop flying blind.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Key Features
- Evaluation Without Ground Truth-Most classic evaluation setups require a carefully curated dataset of “correct” answers. Ragas flips this. By analyzing the relationship between the user’s query, what was retrieved, and what was generated, it can score your pipeline on live traffic, no annotators required.
- The Four Metrics That Matter-At its heart, Ragas evaluates four things:
- Faithfulness – Ragas extracts individual claims from the answer and cross-checks each one against the source context.
- Answer Relevancy – A model may accurately use the retrieved context and still generate an answer that doesn’t address the user’s question. This metric is designed to catch that.
- Context Precision – When the retriever pulls five chunks, are the useful ones ranked at the top? Noise at the top of the context window degrades generation quality, and this metric surfaces that problem.
- Context Recall – Did the retriever actually fetch everything needed to answer the question? A high-recall retriever leaves nothing important behind.
- Define Your Own Rules-The built-in metrics are helpful, but they won’t cover every business need. With Ragas’ AspectCritic, you can define your own evaluation criteria in plain language, essentially teaching the evaluator what “good” looks like for your use case.
- Works With Your Stack – Whether you’re on LangChain, LlamaIndex, or Haystack, Ragas slots in without friction. It also connects to observability platforms like Langfuse and MLflow for ongoing production monitoring.
- Synthetic Test Data That Saves Hours – Whether you’re on LangChain, LlamaIndex, or Haystack, Ragas slots in without friction. It also connects to observability platforms like Langfuse and MLflow for ongoing production monitoring.
Code Examples
Installation
![]()
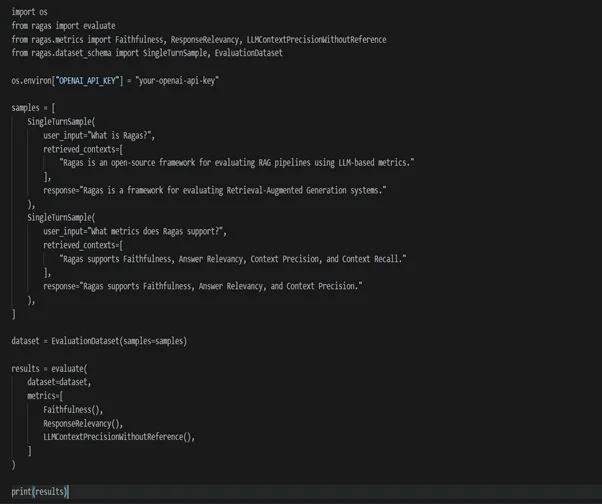
Basic RAG Evaluation
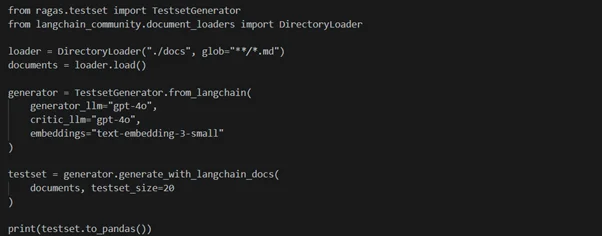
Synthetic Test Dataset Generation
Real-World Use Cases
- Catching hallucinations before users do – Imagine a fintech chatbot answering questions from regulatory documents. One incorrect number or made-up clause could create serious compliance issues. By running Ragas faithfulness checks on responses during staging, teams get an automated safety layer that scales far beyond manual review.
- Improving systems with real evidence – A team replaces traditional keyword search with a vector-based retriever and wants to know if the change actually helped. Instead of relying on assumptions or lengthy A/B testing, Ragas provides clear context, precision, and recall scores within minutes.
- Monitoring quality in production – One SaaS team combines Ragas with Langfuse to continuously evaluate sampled production queries. When answer relevancy drops after a model update, the team gets alerted before customers start raising support tickets.
- Comparing models objectively – An engineering team evaluating GPT-4o vs. Claude vs. a fine-tuned open-source model runs the same benchmark dataset through each. It lets Ragas score them side-by-side, removing gut feel from a budget-impacting decision.
- Evaluating AI agents — For teams building multi-step agents that call tools and plan over time, Ragas provides agent-specific metrics like tool-call accuracy and goal-completion rate, bringing the same rigor to agentic systems that it brought to basic RAG.
Conclusion
The hardest part of building a RAG system isn’t creating the pipeline, it’s knowing when the system is actually reliable. Gut feeling and a few successful demos can only tell you so much. What teams really need is a consistent way to measure quality, track improvements, and catch issues early.
Automated evaluation still works best alongside thoughtful review. But as a foundation for evaluation-driven AI development, it provides teams with a scalable, practical way to improve systems with confidence.
Drop a query if you have any questions regarding the RAG system, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Do I need a labeled dataset to use Ragas?
ANS: – No, that’s actually one of its biggest advantages. Ragas is built for reference-free evaluation. Most metrics work directly from the query, retrieved context, and response. Some metrics optionally accept reference answers if you have them, but they’re not required.
2. Which LLMs can I use as the evaluation judge?
ANS: – The default is OpenAI, but Ragas works with Claude, Gemini, IBM Granite, any Hugging Face model, and local models running through Ollama. You’re not locked into a single provider.
3. Is Ragas only useful for RAG pipelines?
ANS: – Not at all. While RAG evaluation is where it shines, Ragas handles standalone LLM output scoring, summarization, SQL generation accuracy, agent evaluation, and custom-defined criteria. Think of it as a general-purpose LLM evaluation toolkit with very strong RAG support.

WRITTEN BY Livi Johari
Livi Johari is a Research Associate at CloudThat with a keen interest in Data Science, Artificial Intelligence (AI), and the Internet of Things (IoT). She is passionate about building intelligent, data-driven solutions that integrate AI with connected devices to enable smarter automation and real-time decision-making. In her free time, she enjoys learning new programming languages and exploring emerging technologies to stay current with the latest innovations in AI, data analytics, and AIoT ecosystems.










Comments