

 Login
Login

 June 19, 2026
June 19, 2026|
Voiced by Amazon Polly |
Data engineering in 2026 has evolved far beyond traditional extract, transform, and load (ETL) pipelines. Modern enterprises are dealing with ever-growing data volumes, real-time analytics demands, and increasingly AI-driven workloads. Choosing the right processing approach, streaming vs batch, is critical to building scalable, cost-effective, and high-performing data systems. In this article, we explore the key differences between streaming and batch processing, their advantages and limitations, and how to implement them effectively using AWS services.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
Understanding Batch Processing
Batch processing is the classic approach to data processing, where data is collected over time and processed as a single unit, or “batch.” It is ideal for workloads that do not require immediate insights, such as end-of-day reports, historical analytics, or large-scale transformations.
Characteristics of Batch Processing
- High throughput: Processes large volumes of data efficiently.
- Periodic execution: Runs on a schedule (hourly, daily, weekly).
- Latency-tolerant: Delays in processing do not impact business operations immediately.
- Simpler architecture: Typically, easier to design and maintain compared to streaming systems.
AWS Services for Batch Processing
AWS provides a robust ecosystem for batch workloads:
- Amazon S3 + AWS Glue: S3 acts as a scalable data lake, while Glue handles ETL transformations.
- Amazon EMR: Managed Hadoop/Spark clusters for large-scale batch analytics.
- Amazon Redshift: Optimized for batch analytics and large queries.
- AWS Batch: Automatically provisions compute resources for batch workloads.
Example Use Case:
An e-commerce company generates millions of transactional records daily. Running an end-of-day batch pipeline to aggregate sales, calculate revenue, and update dashboards is efficient and cost-effective.
Understanding Streaming Processing
Streaming, or real-time processing, handles data continuously as it arrives. This approach is essential when organizations need instant insights, event-driven actions, or real-time dashboards.
Characteristics of Streaming Processing
- Low latency: Processes data in near real-time.
- Event-driven: Triggers actions as new data arrives.
- Complex architecture: Requires robust orchestration and monitoring to handle errors and data quality.
- Scalability: Must scale to handle bursts in incoming data.
AWS Services for Streaming
AWS offers several services designed for high-performance streaming:
- Amazon Kinesis Data Streams: Ingest and process massive streams of data in real-time.
- Amazon Kinesis Data Analytics: Analyze streaming data using SQL or Apache Flink.
- AWS Lambda: Event-driven compute that reacts instantly to incoming data.
- Amazon MSK (Managed Streaming for Kafka): Kafka-compatible service for complex streaming pipelines.
- Amazon OpenSearch or DynamoDB Streams: For real-time search, analytics, or updates.
Example Use Case:
A financial services firm needs to detect fraudulent transactions in real time. Streaming pipelines using Kinesis, Lambda, and DynamoDB Streams can analyze transactions in real time and trigger alerts within milliseconds.
Key Differences Between Streaming and Batch Processing
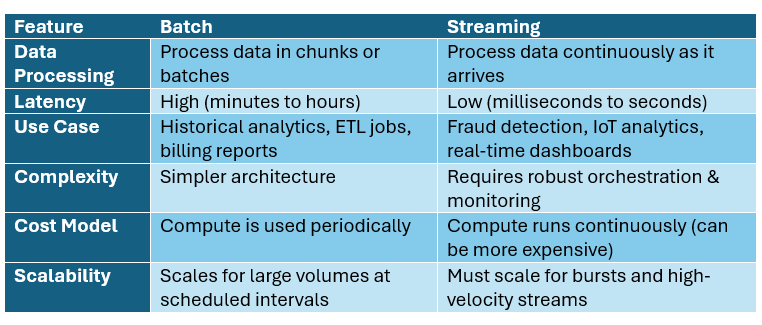
When to Use Batch Processing
Batch processing is preferable in the following scenarios:
- Historical Analysis: When analyzing large volumes of historical data.
- Cost Efficiency: For workloads where real-time processing is unnecessary, batch pipelines reduce compute costs.
- Complex Transformations: Large-scale joins, aggregations, or ETL processes are easier in batch systems.
- Predictable Workloads: Jobs that run on a fixed schedule and have stable data volumes.
AWS Best Practices for Batch:
- Use AWS Glue for ETL pipelines to simplify data transformations.
- Store raw and processed data in Amazon S3, which integrates with multiple analytics services.
- Leverage Amazon Redshift Spectrum for querying data directly from S3 without moving it.
When to Use Streaming Processing
Streaming is the right choice when:
- Real-Time Decision Making: Applications require instant insights or actions.
- High-Velocity Data: IoT devices, clickstreams, social media feeds, or financial transactions.
- Event-Driven Architectures: Microservices that react to incoming data events.
- Monitoring and Alerting: System health, fraud detection, or security monitoring.
AWS Best Practices for Streaming:
- Use Kinesis Data Streams for ingestion of high-throughput data.
- Apply Flink-based analytics with Kinesis Data Analytics for near-real-time processing.
- For serverless streaming, combine Lambda + DynamoDB Streams for automatic scaling and simplified operations.
Hybrid Approaches: The Best of Both Worlds
Many enterprises are adopting hybrid pipelines that combine batch and streaming:
- Lambda + S3 + Glue: Use streaming for real-time insights, then batch for historical analytics.
- Kinesis + Redshift: Stream data for dashboards and aggregate in batch for long-term analytics.
- RAG Pipelines for AI: Use streaming for ingestion and batch for model retraining and embedding updates.
Hybrid approaches balance cost, latency, and complexity, providing flexibility for both operational and analytical needs.
Cost Considerations
When deciding between batch and streaming, cost plays a significant role:
- Batch: You pay for compute only when jobs run. Good for predictable workloads.
- Streaming: Continuous compute usage can increase costs. Optimize with Lambda and auto-scaling, or with Kinesis shard management.
- Data Storage: Streaming may require temporary storage to process events; batch can leverage cheaper storage, such as S3 Glacier, for archival data.
Choosing the Right Data Strategy
Choosing between batch and streaming processing in AWS depends on business requirements, latency tolerance, data volume, and cost considerations.
- Use batch processing for large-scale ETL, historical analysis, and cost-efficient workloads.
- Use streaming processing for real-time insights, event-driven systems, and rapid decision-making.
- Consider hybrid pipelines to combine the strengths of both approaches.
With AWS services like S3, Glue, EMR, Kinesis, Lambda, and Redshift, data engineers can design pipelines that are scalable, flexible, and future-proof, ensuring their organization can handle both today’s data challenges and tomorrow’s AI-driven workloads.
Choosing the right architecture is not just a technical decision; it is a strategic business decision that can impact customer experience, operational efficiency, and revenue growth.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Shabana R
Shabana is a Subject Matter Expert at CloudThat, specializing in AWS with deep expertise across Generative AI, Machine Learning, Data Analytics, Developer Tools, Databases, and Solutions Architecture. A Champion AWS Authorized Instructor & AAI with AWS, and MCT with Azure, Azure certifications, she has empowered over 500+ professionals globally. Known for simplifying complex cloud concepts, Shabana brings 6+ years of industry experience and a passion for continuous learning to every training session.











Comments