

 Login
Login

 June 16, 2026
June 16, 2026|
Voiced by Amazon Polly |
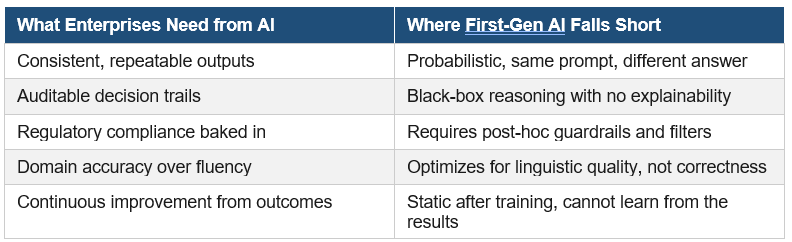
Enterprises no longer struggle to build generative AI prototypes. They struggle to trust them in production. Over the past year, organizations rapidly adopted LLMs for copilots, assistants, and automation, yet many deployments remain stuck in pilot stages because enterprise AI must meet a far higher bar than consumer AI.
A 90% accurate chatbot is impressive. A 90% accurate financial assistant is a liability.
Two major AWS announcements directly address this trust gap: Reinforcement Fine-Tuning in Amazon Bedrock and the Amazon Nova foundation model family. Together, they signal a decisive shift from creative AI to reliable enterprise AI.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
The Enterprise AI Reliability Gap
Despite rapid adoption, the production rollout of generative AI has been slower than expected. The root cause is not capability; it is predictability. Consumer AI prioritizes creativity and flexibility. Enterprise AI requires risk reduction and accountability.
Organizations discovered that prompt engineering, RAG pipelines, and traditional fine-tuning improve responses, but don’t truly optimize behavior. Reinforcement fine-tuning changes that equation fundamentally.
What Reinforcement Fine-Tuning Actually Solves
Reinforcement fine-tuning introduces a fundamentally different learning paradigm. Instead of training on static datasets, models learn from feedback aligned to real business outcomes, reward signals, human evaluation, task success criteria, and domain-specific metrics.
The shift: “Predict the next word.” → “Achieve the desired outcome.”
This is the most important conceptual shift in enterprise AI maturity. Think of it as performance management for AI; the model is not just learning what sounds right, but what works.
| Use Case: Financial Services Compliance
A global bank deployed an LLM to generate credit risk summaries. Traditional fine-tuning improved fluency but not regulatory accuracy. After applying reinforcement fine-tuning with compliance officer feedback as reward signals, the model’s policy-compliant output rate rose from 71% to 94%, clearing the internal threshold for production deployment. The feedback loop also surfaced edge cases that manual prompt engineering had missed entirely. |
Four Dimensions RFT Optimizes
Reinforcement fine-tuning enables enterprises to optimize AI across four critical dimensions simultaneously:
- Accuracy- models learn preferred answers, not just probable ones, significantly reducing hallucinations
- Compliance- regulatory policies are embedded directly into the training reward loop
- Domain expertise- models learn what “good” looks like in specific industries and workflows
- Decision quality- AI optimizes for task success, not linguistic fluency
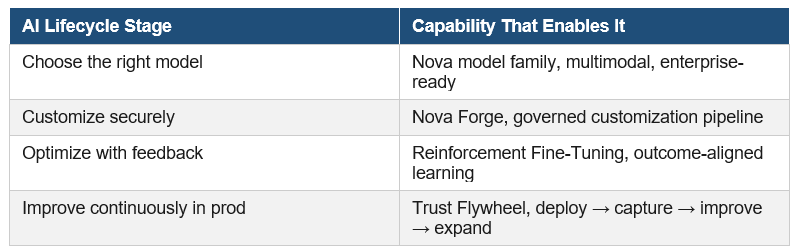
Amazon Nova: The Enterprise Foundation Model Strategy
While reinforcement tuning improves behavior, enterprises need the right base models to tune against. The Amazon Nova family introduces a multimodal, enterprise-focused model stack designed for customization at scale, not just capability at launch.

| Use Case: Healthcare Multimodal Diagnostics
A hospital network uses Nova to analyze patient records (text), radiology scans (image), and consultation recordings (speech) in a unified pipeline. Rather than stitching together three separate models with custom integrations, Nova processes all modalities natively, reducing integration complexity by 60% and enabling richer clinical context for AI-assisted diagnostic support. |
Nova Forge: Safe, Continuous Model Customization
The most strategically significant component of the Nova announcement is Nova Forge. Enterprises do not want generic, one-size-fits-all intelligence. They want domain-specific models that embed proprietary knowledge and evolve safely over time.
Nova Forge provides a governed path to customize models securely, tune continuously based on production feedback, and manage model lifecycle end-to-end, closing the gap between model experimentation and production operations.
The Full AI Lifecycle Platform
Combined, these capabilities create something enterprises have lacked: a complete AI lifecycle platform that mirrors the DevOps transformation from manual releases to continuous delivery.
We are witnessing ModelOps becoming Continuous Intelligence. AI that gets better the more it works, aligned to the outcomes that matter to the business, not to generic benchmark scores.
From Experimentation to Production-Ready AI
Generative AI began as a revolution in creativity. It is now becoming an operations revolution. Reinforcement fine-tuning and the Nova model family deliver the missing ingredients enterprises need: reliability, governance, and continuous improvement.
The future of enterprise AI will not be defined by the smartest model. It will be defined by the model that learns from feedback, improves continuously, and aligns with business outcomes. With these announcements, AWS is building exactly that infrastructure.
The era of production-ready enterprise AI has begun.
Reliable Enterprise AI
Reinforcement fine-tuning and Amazon Nova are not incremental updates; they are a structural shift in how enterprise AI is built. RFT closes the trust gap by aligning model behavior to real business outcomes. Nova further closes the loop with a multimodal foundation that enterprises can customize and govern at scale. Together, they deliver what first-generation GenAI could not: reliability that holds in production.
The enterprises that lead the next phase will stop measuring AI success by model accuracy alone and start measuring by business impact, regulatory standing, and improvement velocity. AWS has built the infrastructure. The competitive advantage belongs to the teams that deploy it with intent.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat
FAQs
1. How is reinforcement fine-tuning different from standard fine-tuning?
ANS: – Standard fine-tuning shows a model what correct answers look like. RFT trains it to optimize for outcomes using reward signals, compliance scores, expert ratings, or task success rates. The model learns to pursue the right result rather than imitate one, which means fewer edge-case failures and genuine improvement as production feedback accumulates.
2. Which industries benefit most from Amazon Nova’s multimodal capabilities?
ANS: – Healthcare, financial services, and manufacturing gain the most. Healthcare unifies patient records, imaging, and consultation audio into a single pipeline. Financial services combine contracts, charts, and call recordings for richer risk analysis. Manufacturers merge sensor data, visual inspections, and maintenance logs to enable predictive maintenance. Any industry where critical information spans multiple formats will see meaningful gains in context quality and decision accuracy.
3. What does an enterprise need in place before adopting reinforcement fine-tuning?
ANS: – Three prerequisites matter most: defined success criteria, a feedback capture mechanism, and domain expert involvement. Without clear metrics, there is no reward signal to train against. Without structured production feedback, the improvement loop cannot close. Without domain experts defining what “good” means, the model risks optimizing for the wrong goal. Build these foundations first, and RFT delivers dramatically better results than treating it as a plug-and-play upgrade.

WRITTEN BY Shruti Bijawat
Shruti Bijawat is a Business Unit Head at CloudThat Technologies Private Limited, with deep specialization in Generative AI and Machine Learning. She is a Champion Amazon Authorized Instructor and a NVIDIA Certified Instructor, bringing over 16 years of combined industry and academic experience. Shruti has enabled thousands of professionals to upskill in cloud architecture, GenAI, and ML, delivering programs that balance strong conceptual foundations with real-world implementation. Known for her ability to customize training delivery based on participant profiles, she consistently translates complex technical concepts into practical, outcome-driven learning experiences. Her passion for learning and development is reflected in her structured, hands-on, and impact-focused teaching approach.











Comments