

 Login
Login

 August 18, 2025
August 18, 2025|
Voiced by Amazon Polly |
Overview
Apache HBase is a distributed, non-relational database that excels at managing large-scale, sparse datasets with real-time read/write capabilities. When deployed on Amazon EMR (Elastic MapReduce), it brings scalability, flexibility, and cost-efficiency to modern big data workflows.
This blog explores the architecture of Apache HBase, its integration with Amazon EMR, how Apache Phoenix enhances usability with SQL access, and recommended best practices for a production-grade deployment.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction to Apache HBase
Apache HBase is modeled after Google’s BigTable and is designed for fast, random access to large amounts of structured and semi-structured data. Unlike traditional relational databases, HBase is column-oriented and schema-less, which means rows can have varying columns and structures.
HBase stores data as key-value pairs where:
- A row key uniquely identifies each row.
- Data is grouped in column families.
- Each cell is versioned using timestamps.
The architecture supports scalability to hundreds of nodes, enabling applications to store billions of rows and millions of columns.
Core Components of HBase
HBase is built using a set of distributed components, each performing a specific function:
- HMaster: Manages the assignment of regions to servers and maintains cluster metadata.
- HRegionServer: Hosts and serves data to clients, handles read/write operations, and manages region splitting and merging.
- MemStore: Temporarily stores new writes in memory before flushing them to disk.
- HFile: The underlying file format that stores HDFS or Amazon S3 data.
- WAL (Write-Ahead Log): Ensures durability by logging changes before writing them to MemStore.
Regions are subsets of data and are distributed across RegionServers. These can be split automatically or manually to balance load and improve performance.
Running HBase on Amazon EMR
Amazon EMR allows you to deploy HBase with HDFS or Amazon S3 as the storage backend. Each approach offers different advantages:
HBase on HDFS
This traditional setup provides high throughput for read/write operations and low latency. It is well-suited for workloads where availability and performance are critical, and where some data loss is acceptable due to data replay capabilities.
HBase on Amazon S3
With support introduced in Amazon EMR 5.2.0, running HBase on Amazon S3 decouples storage from compute, allowing clusters to be turned off when not in use. It offers improved durability, flexibility, and cost efficiency, especially for read-heavy workloads or archival use cases.
HBase on Amazon S3 supports:
- Persistent HFile tracking
- Read-replica clusters
- Snapshot backups to Amazon S3
- Simpler cluster scaling and shutdown
Comparing HDFS and Amazon S3 as Storage Backends
Choosing between HDFS and Amazon S3 depends on the nature of your workload:
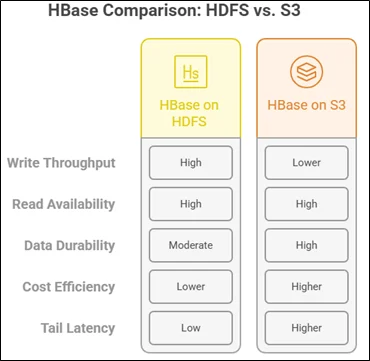
HBase on Amazon S3 is particularly beneficial for cost-sensitive environments, while HDFS remains ideal for high-performance scenarios.
SQL Capabilities with Apache Phoenix
Apache Phoenix is a relational layer over HBase that enables SQL querying using JDBC. It translates SQL queries into HBase API calls, making HBase accessible to users familiar with traditional databases.
Phoenix provides:
- SQL access using standard JDBC
- Server-side filtering and aggregation
- Secondary and functional indexes
- ACID transaction support
Using co-processors, Phoenix improves performance by pushing filters and computations down to the HBase server level.
Migrating HBase Workloads to Amazon EMR
Organizations can migrate their on-prem HBase workloads to Amazon EMR using a snapshot-based process:
- Create a snapshot of the existing HBase tables.
- Export the snapshot to Amazon S3 using tools like HBase snapshot export.
- Launch an EMR cluster, pointing the HBase root directory to the Amazon S3 location.
- Restore the snapshot using the HBase shell or clone_snapshot to create new tables.
AWS support can assist with Amazon S3 prefix pre-partitioning to improve performance during import and restore.
Best Practices for Running HBase on Amazon EMR
On HDFS:
- Use multi-leader clusters across availability zones for high availability.
- Pre-split tables are used to ensure data distribution is even and avoid write hotspots.
- Export regular snapshots to Amazon S3 for backup.
- Use local instance storage (e.g., i3en, r5d) for high-performance I/O.
On Amazon S3:
- Avoid auto-scaling and spot instances to prevent region instability.
- Pre-partition HBase region directories on Amazon S3 to reduce throttling errors.
- Adjust EMRFS parameters like fs.s3.maxRetries and fs.s3.maxConnections for performance.
- Use BlockCache and BucketCache to enhance read efficiency.
- Flush and disable tables before cluster shutdown to prevent data loss.
Monitoring and Troubleshooting
Monitoring can be performed using:
- HBase Web UI
- Hue Browser
- Ganglia
- Amazon Managed Prometheus and Grafana
Logs for HMaster and RegionServer processes are available on the cluster and can be sent to Amazon S3 for centralized access.
Troubleshooting Tools
- HBCK (HBase Check): Identifies and fixes table inconsistencies, stuck regions, and metadata issues.
- Snapshot and Compaction Monitoring: Helps maintain performance and data integrity.
Benchmarking with YCSB
Before production deployment, it’s recommended to use Yahoo! Cloud Serving Benchmark (YCSB) to test performance. Key steps include:
- Installing YCSB on an Amazon EC2 instance.
- Adjusting payload size and workload proportions.
- Running multiple jobs in parallel to simulate production load.
- Comparing performance between Amazon S3 and HDFS configurations.
This provides insights into how your workload will perform under real-world conditions.
Conclusion
Apache HBase on Amazon EMR offers a scalable, flexible, and cost-effective solution for big data applications requiring real-time access to large datasets.
With Apache Phoenix, users can leverage the power of SQL over HBase, simplifying development and analytics. By following best practices in deployment, monitoring, and benchmarking, organizations can build a responsive data infrastructure using HBase on Amazon EMR.
Drop a query if you have any questions regarding Amazon EMR and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is Apache HBase used for?
ANS: – Apache HBase is used for real-time read/write access to large, sparse datasets in a distributed NoSQL environment.
2. Why run HBase on Amazon EMR?
ANS: – Running HBase on Amazon EMR provides scalability, flexibility, and cost-efficiency by leveraging AWS-managed infrastructure.
3. When should I choose Amazon S3 over HDFS for HBase storage?
ANS: – Choose Amazon S3 for cost savings and durability in read-heavy workloads where higher write latency is acceptable.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments