

 Login
Login

 August 28, 2025
August 28, 2025|
Voiced by Amazon Polly |
In the era of big data and lightning-fast decision-making, the demand for real-time analytics has never been higher. Organizations need modern, scalable solutions that process massive amounts of data quickly, without worrying about infrastructure provisioning or performance bottlenecks. Enter Amazon Redshift Serverless and Apache Iceberg – a game-changing duo for real-time, cloud-native analytics on AWS.
In this blog, we’ll explore how Redshift Serverless and Apache Iceberg together enable blazing-fast insights from your data lake, with flexibility, open formats, and zero infrastructure headaches.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
What is Amazon Redshift Serverless?
Amazon Redshift Serverless is a fully managed, on-demand version of AWS’s flagship cloud data warehouse, eliminating the need to manage infrastructure. It allows you to run analytics without managing clusters or worrying about capacity. You only pay for the compute you use, and the system automatically scales up or down based on query demand.
Key Benefits:
- Instant provisioning – no cluster setup needed.
- Auto-scaling compute based on workload.
- Provides seamless connectivity with Amazon S3, Glue Data Catalog, and AWS analytics services for centralized data access, governance, and processing.
- Pay-per-use pricing – great for unpredictable or bursty workloads.
What is Apache Iceberg?
Apache Iceberg is an open table format designed for big data Lakehouses. It brings ACID transactions, schema evolution, partitioning, and time travel to your S3-based data lakes – solving many limitations of older formats like Hive or Parquet.
Key Features:
- Open standard, supported by engines like Redshift, Athena, Spark, and Flink.
- Optimized for both batch and streaming workloads.
- Supports real-time ingestion and incremental querying.
- Enables multiple query engines to access the same data lake simultaneously.
Why Combine Redshift Serverless and Iceberg?
While Redshift provides powerful analytics capabilities, Apache Iceberg unlocks open table format compatibility, better data lake management, and real-time ingestion features.
Use Case Scenario:
You want to:
- Ingest streaming data into S3 in real time.
- Query this data instantly using Redshift Serverless.
- Keep the data lake open and shareable with other engines like Athena or Spark.
- Ensure fast performance without provisioning infrastructure.
With Redshift Serverless and Iceberg, all of the above becomes possible.
Architecture Overview
Modern data platforms are evolving from rigid warehouses to open, scalable Lakehouse architectures. Amazon Redshift Serverless and Apache Iceberg together represent the cutting edge of this shift — offering real-time, cost-effective analytics on data stored in Amazon S3 with open format support and high performance.
Let’s explore a step-by-step breakdown of how the architecture works and how each AWS service fits into the real-time data pipeline.
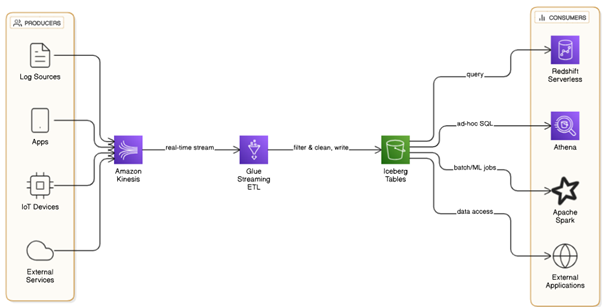
- Data Producers
Sources such as:
- Mobile apps, websites, APIs
- IoT devices, sensors, clickstreams
- Operational databases or CRMs
These generate event-based or transactional data in real-time that needs to be ingested and processed with minimal latency.
- Amazon Kinesis Data Streams / Firehose
Kinesis acts as the real-time data ingestion layer, collecting high-velocity data from producers and delivering it to downstream processing systems.
- Kinesis Data Streams: Allows for millisecond-latency ingestion and custom consumers (e.g., Glue, Lambda).
- Kinesis Firehose: Simplifies delivery of streaming data directly into S3, Redshift, or other destinations.
Use Firehose if you want minimal configuration; use Streams for complex processing and transformation logic.
- AWS Glue Streaming ETL Jobs
AWS Glue Streaming Jobs continuously process real-time data from Kinesis, apply necessary transformations (e.g., schema mapping, data cleansing), and store the results as Iceberg format files on Amazon S3.
Key steps:
- Convert incoming data to Apache Iceberg format
- Partition data (e.g., by timestamp, region, customer ID)
- Register and manage table schema with AWS Glue Data Catalog
With native support for Apache Iceberg from version 4.0 onward, AWS Glue enables automatic schema evolution for flexible and scalable data lake management.
- Apache Iceberg on Amazon S3
Iceberg provides a transactional, open table format on top of object storage (Amazon S3). It enables:
- Atomic inserts, updates, deletes
- Time travel queries (rollback or historical analysis)
- Schema evolution without manual rewriting
- Partition pruning and column-level optimization
This layer forms the heart of your Lakehouse architecture – combining data lake cost-efficiency with warehouse-level capabilities.
- Glue Data Catalog (Metastore)
AWS Glue acts as the central metadata repository for Iceberg tables — allowing all services (Redshift, Athena, Spark) to access the same schema and data location transparently.
- Column-level schema definition
- Table-level security via Lake Formation
- Integration with AWS Lake Formation for access control and lineage tracking
- Amazon Redshift Serverless
With Redshift Serverless, you can run highly scalable, on-demand analytics directly on Iceberg tables managed through the AWS Glue Data Catalog – without managing any infrastructure.
- Spectrum-based querying over Iceberg format
- Materialized views for caching hot queries
- Automatic scaling based on concurrent usage
No infrastructure to manage – Redshift Serverless scales compute independently of storage.
- Amazon Athena
Athena is a serverless interactive query engine that also supports Iceberg tables. It’s ideal for:
- Ad-hoc analysis
- Data validation and exploration
- Pre-ingestion checks
Amazon Athena provides serverless, SQL-based access to data in S3, supporting Iceberg, JSON, Parquet, and CSV file formats, with native integration into AWS Glue for centralized metadata and governance.
- Apache Spark on EMR / Glue
For advanced analytics, machine learning, or data science workloads, you can use Apache Spark (via EMR or AWS Glue Notebooks) to read from Iceberg tables. It helps in
- Model training on real-time datasets
- Batch processing
- Predictive analytics
Since Iceberg is an open format, Spark reads the same datasets with full compatibility.
Performance Optimization Tips
To ensure lightning-fast analytics, follow these best practices:
- Partition smartly – Use fields like event_time for efficient pruning.
- Leverage materialized views in Redshift for caching hot data.
- Use columnar compression (Snappy, ZSTD) for lower storage and faster reads.
- Use Iceberg table snapshots to enable auditing and run historical queries.
Security and Governance
A secure and well-governed data architecture is essential when working with sensitive or large-scale datasets in the cloud. AWS provides a suite of integrated services to ensure your data remains protected, compliant, and accessible only to authorized users.
- Manage Access with AWS Lake Formation
Configure access policies for Apache Iceberg tables using Lake Formation to define permissions at the table, column, or row level, helping ensure secure and compliant data usage.
- Centralize Metadata with AWS Glue Data Catalog
Utilize the Glue Data Catalog as your single source of truth for metadata, enabling consistent schema enforcement, lineage visibility, and seamless interoperability across analytics services like Athena, Redshift, and Spark.
- Enable Auditing with AWS CloudTrail and S3 Logging
Activate CloudTrail to monitor API activities and turn on S3 access logs to track who accessed what data, helping maintain transparency and meet auditing or regulatory requirements.
- Implement Fine-Grained Access Controls
Use IAM policies in combination with Amazon Redshift’s access control features to manage precise user permissions at the resource and query level, ensuring only the right people have access to specific datasets.
Real-World Use Cases
- E-Commerce Analytics
Track user sessions, product views, and cart activity in real time, and analyze them using Redshift dashboards.
- Healthcare Monitoring
Stream device data into Iceberg and run anomaly detection queries with Redshift Serverless.
- Financial Fraud Detection
Ingest financial transactions in real time and perform fraud detection using Amazon Redshift analytics, triggering automated alerts for suspicious behaviour.
Cost Efficiency
With Redshift Serverless:
- You only pay for what you query (no idle cluster costs).
- Iceberg lets you store data on S3 cheaply and access it across tools.
- This combination reduces total cost of ownership (TCO) while increasing flexibility.
Conclusion
As data becomes more real-time and diverse, traditional data warehouse models fall short. The combination of Amazon Redshift Serverless and Apache Iceberg empowers businesses to build real-time, scalable, and open analytics architectures with ease.
Whether you’re a data engineer, architect, or analyst, this modern approach helps you:
- Eliminate infrastructure headaches
- Achieve lightning-fast queries
- Work with open, interoperable formats
References
- What is Amazon Redshift? – Amazon Redshift
- Getting started with Apache Iceberg tables in Amazon Athena SQL – AWS Prescriptive Guidance
- Using the Iceberg framework in AWS Glue – AWS Glue
- Data lake design patterns and principles – Best Practices for Building a Data Lake on AWS for Games
- Amazon Redshift Serverless feature overview – Amazon Redshift
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Nitin Kamble
Nitin Kamble is a Subject Matter Expert and Champion AAI at CloudThat, specializing in Cloud Computing, AI/ML, and Data Engineering. With over 21 years of experience in the Tech Industry, he has trained more than 10,000 professionals and students to upskill in cutting-edge technologies like AWS, Azure and Databricks. Known for simplifying complex concepts, delivering hands-on labs, and sharing real-world industry use cases, Nitin brings deep technical expertise and practical insight to every learning experience. His passion for bike riding and road trips fuels his dynamic and adventurous approach to learning and development, making every session both engaging and impactful.











Comments