

 Login
Login- Consulting
- Training
- Partners
- About Us
x
AWS, Cloud Computing
 8 Mins Read
8 Mins Read

 July 11, 2022
July 11, 2022
Prometheus is an open-source monitoring and alerting tool used to monitor the resource utilization and health of resources running on-premises and on various cloud platforms. Conceptualized and built at SoundCloud, Prometheus has been in the market since early 2012. Many organizations have integrated Prometheus into their environment due to its ease of use and cost. It is constantly being updated/upgraded by a robust community of developers and a vast user base. In 2016, Prometheus joined the CNCF community, which also governs Kubernetes.
Metrics are essential in understanding the resource utilization by host machines and applications, which help businesses do the right Capacity Planning, reduce user latency, avoid downtime of their applications, and design highly available & load-balanced infrastructure. Time Series metrics allow measuring various resource consumption like CPU, Memory, R/W, IOPS, and Network in & out traffic over periodic intervals. Numerous applications offer to monitor the “Time Series” data; Prometheus is at the forefront of these applications.
Prometheus mostly works through a Pull-based model of gathering data exposed via HTTP endpoints of the targets. A push-based data gathering can be achieved through a Push-gateway setup. Prometheus architecture can be divided into five components.
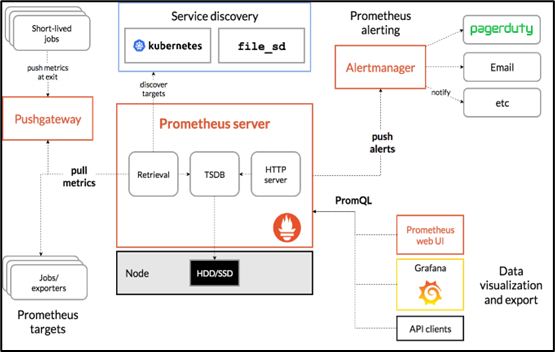
Since its inception in 2014, Grafana has become the de-facto open-source Alerting and Visualization tool for organizations. The main feature of Grafana that makes it stand out is that the data source for Grafana can reside anywhere and everything can be gathered and visualized on a single dashboard. Grafana offers a wide variety of options for ready templates based on the tools or services being used and the panels on each of the templates are also customizable. These dynamic dashboards can be shared with team members for collaborative visualization and can be securely accessed by an admin user using passwords or security tokens.
Grafana can easily integrate with many third-party tools like Graphite, Prometheus, Influx DB, ElasticSearch, MySQL, and PostgreSQL using plugins. Grafana can be accessed on a web browser. Grafana provides access to real-time streaming data from various sources and this data can be visualized using charts, bar/line graphs, histograms, and pie charts. Using the same query language of the source, Grafana collects data sets from the source for visualization.

On AWS sign-in using non-root account User credentials with “AdministratorAccess” to create IAM roles & policies for accessing & managing other AWS resources.
a) IAM Roles to be created:
On the IAM service page, create the following roles for EKS Cluster and Node groups to access other AWS resources/services. The “Trusted Entity Type” needs to be “AWS service”. Under “Use Case”, type “EKS” and create the below roles:
Give the role a unique name: “AmazonEKSNodeRole” and create the role.
Apart from the above policies, many other policies get created while creating the Managed Node Group and installing other Tools like Helm, Prometheus & Grafana, which AWS automatically creates for us.
b) Creating VPC, Subnet & Security Groups:
Default VPC, Subnet, and Security Groups can be used while creating an EKS Cluster. However, as security best practice, it is always good to create custom VPC, Subnet & SG’s with specific IP ranges, Ingress & Egress. With custom VPC, Internet Gateway and Route table need to be created and attached to the VPC.
c) Creating EKS Cluster:
d) Adding Managed Linux Node Group to EKS Cluster:
Once the EKS cluster is created and shows as “Active”, We can now add Managed node groups (worker nodes) to the cluster.
e) Installing aws cli:
f) Installing kubectl:
g) Installing helm:
h) Connect to AWS, Set Context for EKS, Get svc, nodes, pods:
Metrics Server needs to be installed before installing Prometheus. The raw metrics can be accessed at /metrics.
Helm repo needs to be updated and Prometheus needs to be installed in the Prometheus namespace using the below commands.
Ex: node_disk_info
node_disk_read_bytes_total
node_disk_write_bytes_total
kube_pod_status_ready
kube_daemonset_created
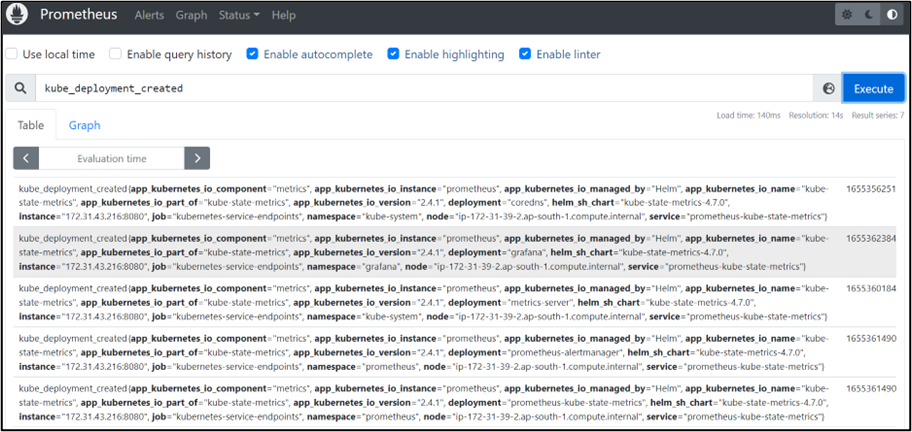
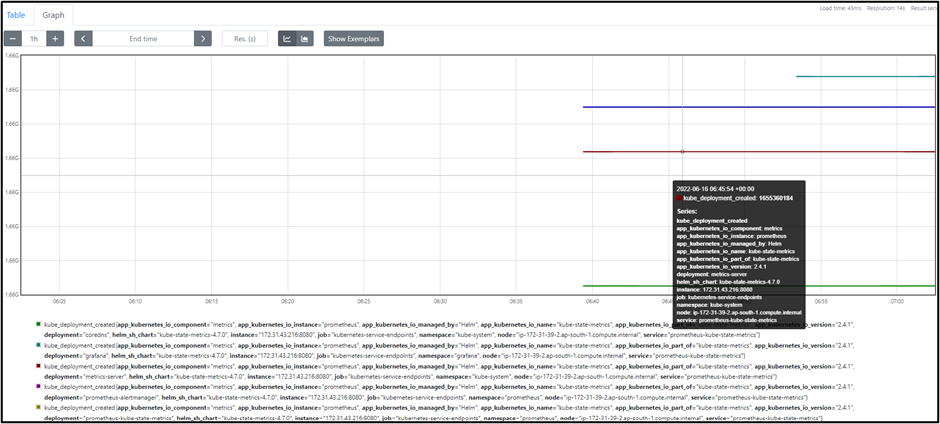
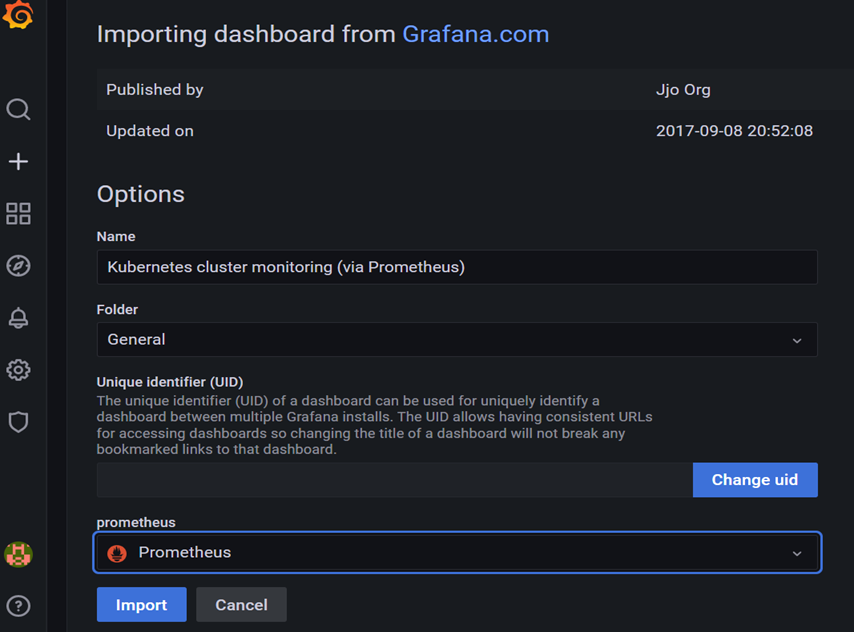
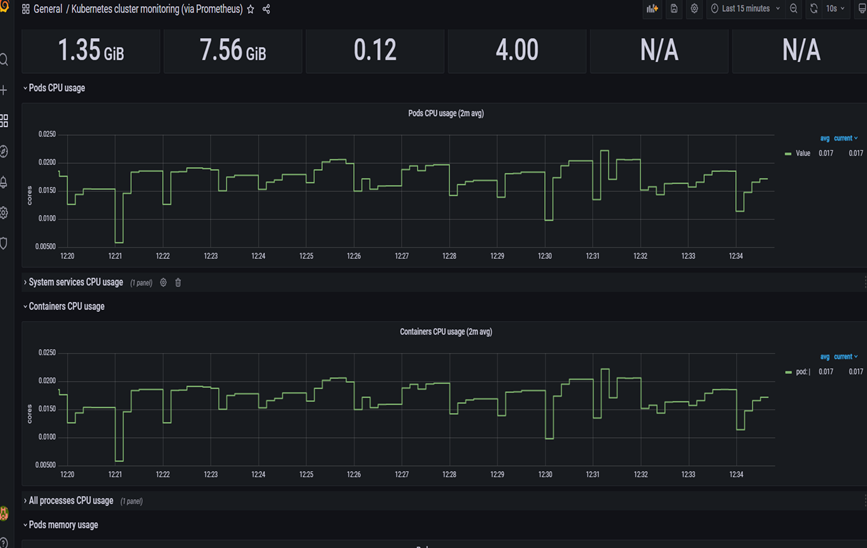
Below are some images from the Prometheus UI dashboard:







CloudThat is the official AWS (Amazon Web Services) Advanced Consulting Partner, Microsoft Gold Partner, Google Cloud Partner, and Training Partner helping people develop knowledge of the cloud and help their businesses aim for higher goals using best-in-industry cloud computing practices and expertise. We are on a mission to build a robust cloud computing ecosystem by disseminating knowledge on technological intricacies within the cloud space. Our blogs, webinars, case studies, and white papers enable all the stakeholders in the cloud computing sphere.
If you have any queries about the AWS EKS cluster, Prometheus and Grafana, or any other services, drop them in the comment section and I will get back to you quickly.
CloudThat is a house of All-Encompassing IT Services on the cloud offering Multi-cloud Security & Compliance, Cloud Enablement Services, Cloud-Native Application Development, and System Integration Services. Explore our consulting here.
Saritha is a Subject Matter Expert - Kubernetes working as a lead at CloudThat. She has relentlessly kept upskilling with the latest trending technologies and delivering the best cloud-native solutions to Businesses in all sectors. She is a Microsoft Certified Solution Architect, Certified Windows Server Administrator, and Windows Networking professional and strives towards providing the best cloud experience to our customers through transparent communication, methodical approach, and diligence.
SHARE

Upcoming Webinar
By divya
Apr 25, 2024




Case Study
By gopi
Apr 22, 2024



Big Data, Cloud Computing
By Pankaj Choudhary
Apr 19, 2024

Case Study
By gopi
Apr 16, 2024

Our support doesn't end here. We have monthly newsletters, study guides, practice questions, and more to assist you in upgrading your cloud career. Subscribe to get them all!
Pavan
Jul 11, 2022
All the best!