

 Login
Login

 November 11, 2025
November 11, 2025|
Voiced by Amazon Polly |
Introduction
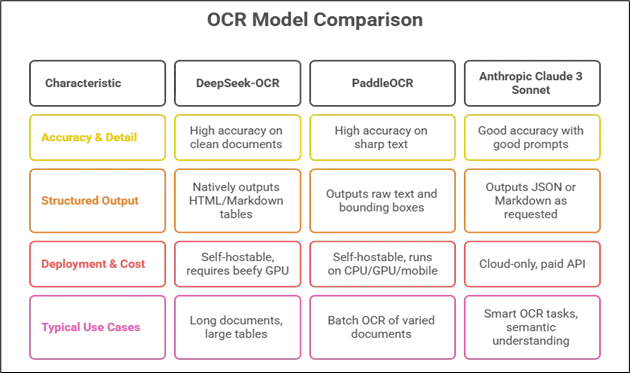
Extracting data from images of spreadsheets (Excel tables) requires an OCR that not only recognizes text but also preserves the table structure. DeepSeek-OCR is a new vision-language OCR model designed for document understanding (tables, charts, math, etc.). PaddleOCR is a mature, open-source OCR toolkit with specialized layout modules. Anthropic’s Claude 3 Sonnet (Sonnet-3) is a general multimodal model accessible via Amazon Bedrock. Each has different strengths for tabular data:
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Parsing Excel Spreadsheet Images for Table Extraction
- DeepSeek-OCR uses a multi-stage vision encoder and a Mixture-of-Experts (MoE) text decoder. It splits images into 16×16 patches, applies SAM for layout, uses a convolutional compressor for token reduction, and employs CLIP-ViT for context. Compressed tokens go to a 3B-parameter MoE LLM to generate text. It is prompt-driven, and outputs can be plain text, Markdown, or HTML tables. In “table parsing” mode, it creates HTML <table> files with <tr>/<td> tags, accurately mapping cells. This design enables the handling of long documents with ~96–97% accuracy even after 10× compression. It is open-source under the MIT license and supports both on-premises and offline use.
- PaddleOCR uses a detection-recognition pipeline (DBNet + CRNN) and PP-Structure modules for forms and tables. It is optimized for printed and scene text in many languages, supporting GPU, CPU, and mobile devices. It outputs text regions and bounding boxes, but not native HTML. Layout tools like PP-StructureV3 detect tables and cells, which can be converted into CSV or DataFrames. PP-OCRv5/3.0 improved accuracy by ~13 points. It is fast, capable of offline use, and ready for production, but it lacks deep reasoning and won’t interpret charts or table logic.
- Anthropic Claude 3 Sonnet (Sonnet-3) is a multimodal LLM on Amazon Bedrock that interprets documents rather than serving as an OCR engine. It converts images into structured formats, such as JSON or Markdown tables, and can extract data from graphs or forms. It is strong in understanding visual elements, but it is proprietary and only available in the cloud. OCR quality decreases with small or noisy text, and cost and latency vary with image complexity.
DeepSeek OCR: Architecture and Table Parsing
DeepSeek-OCR focuses on long documents and complex layouts. Input images (e.g., spreadsheets) are split into 16×16 patches. The DeepEncoder compresses them: SAM detects objects/text, CNN downsamples (16×), and CLIP-ViT captures layout context. The 3B-parameter MoE decoder activates only relevant experts for efficiency. As a language model, it can output structured formats. For example,
|
1 2 3 4 5 |
<table> <tr><td>Country</td><td>GDP</td>...</tr> <tr><td>USA</td><td>21.43T</td>...</tr> ... </table> |
DeepSeek combines detection, recognition, and formatting. At ~10× compression, it achieves ≈96–97% accuracy. Best for clear spreadsheet images where cells are localized. Integration example:
|
1 2 3 4 5 6 7 8 9 10 |
from transformers import AutoTokenizer, AutoModel import torch tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-OCR", trust_remote_code=True) model = AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR", trust_remote_code=True).to("cuda") prompt = "<image>\nConvert the document to HTML." result = model.infer(tokenizer, prompt=prompt, image_file="sheet.png", base_size=1024, image_size=640, crop_mode=False) print(result) # this prints HTML including <table> tags |
Once you have the HTML, you can parse it (e.g., with pandas.read_html) to get a DataFrame. This makes DeepSeek powerful for ETL pipelines that start from spreadsheet images.
PaddleOCR: Traditional OCR Pipeline
PaddleOCR (PP-OCR) is a well-established OCR toolkit that employs a two-step approach: first, it detects text boxes, and then it recognizes the text within each box using a neural recognizer. It also offers end-to-end pipelines: the PP-Structure module adds page layout analysis, identifying tables, forms, and reading order. In a typical use case, you’d run:
|
1 2 3 4 5 6 7 |
from paddleocr import PaddleOCR ocr = PaddleOCR(use_angle_cls=True, lang='en', use_gpu=False) result = ocr.ocr("sheet.png") for line in result: bbox, (text, conf) = line print(text) # each line of text detected |
Each result entry gives the bounding box and the recognized text. PaddleOCR also provides utilities to group text lines into tables if the layout is clear. According to its documentation, the latest PP-OCRv5/3.0 model has significantly improved accuracy across scenarios (↗13 points over v4). The toolkit’s key advantages are reliability and flexibility: it’s open-source (Apache 2.0), can run fully offline on CPUs, GPUs, and mobile devices, and excels at processing printed/scene text. However, it outputs raw text, so additional logic is needed to reconstruct the table rows/columns. Its table extraction (via PP-Structure) is robust but not generative: it won’t, for example, infer blank cells or output JSON without extra coding. For many developers, PaddleOCR is a sensible default: it’s fast, high-quality on clear images, and simple to integrate. In summary: PaddleOCR = proven OCR + layout parsing.
Anthropic Claude 3 Sonnet (Sonnet-3) Vision
Sonnet-3 is an LLM with vision input, not a traditional OCR. It processes images with prompts (via AWS Bedrock) to produce structured outputs, such as JSON or Markdown tables. AWS has demonstrated its ability to interpret maps, charts, and diagrams, for example, by converting a population graph into a table. In IDP pipelines, AWS Lambda invokes Sonnet on scanned documents and stores JSON output in a database.
Sonnet’s strength lies in flexible reasoning, as it can handle blurry or mixed content (text, tables, visuals) and generate coherent, structured data. However, it’s cloud-only, prompt-sensitive, may hallucinate or miss fine details, and has higher latency and cost for large batches. It’s best for AI-driven interpretation of visual data, while plain text extraction remains inconsistent.
Performance and Use-Case Comparison
DeepSeek-OCR, PaddleOCR, and Sonnet-3 serve different but complementary purposes in practice:
- Accuracy & Detail: DeepSeek reaches ~95–97% accuracy on clean docs even with compression. PaddleOCR is equally strong on sharp text, and PP-OCRv5 improves further. Sonnet can approach OCR accuracy with good prompts, but it isn’t benchmarked directly. For error-free text, DeepSeek or PaddleOCR is a safer option. DeepSeek parses tables precisely; PaddleOCR rarely misreads text but may mis-segment tables; Sonnet understands context but might misalign cells if the prompt is weak.
- Structured Output: DeepSeek and Sonnet output structured data, with DeepSeek in HTML/Markdown and Sonnet in JSON/Markdown. PaddleOCR outputs raw text and boxes; assembling tables needs extra code, which PP-Structure helps with.
- Deployment & Cost: DeepSeek (MIT) and PaddleOCR (Apache-2) are open-source and self-hostable. DeepSeek requires a GPU, whereas PaddleOCR runs efficiently on CPUs and scales cost-effectively. Sonnet-3 is cloud-only via Amazon Bedrock, billed per token/image, and can’t run locally. It offers a large context window (up to 200K tokens), but it is often unnecessary for basic OCR
Conclusion
Ultimately, accuracy also depends on testing with your own images. Benchmarks suggest that DeepSeek and Paddle are neck-and-neck in terms of plain OCR accuracy, with DeepSeek having an advantage due to its structured outputs.
Drop a query if you have any questions regarding OCR Models and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Which OCR model gives the most accurate table structure from spreadsheet images?
ANS: – If your primary goal is to keep cells aligned correctly (rows, merged headers, empty cells, etc.), DeepSeek-OCR is currently the best choice.
It can directly output:
- <table>, <tr>, <td> HTML tags
- Markdown tables
- CSV-like formatting
2. Which model should I use for images that are noisy, blurred, scanned, or taken in low light?
ANS: – PaddleOCR is strongest here.
Its detection+recognition pipeline is trained on real-world documents and languages.
Best strategy:
- Use PaddleOCR for text extraction
- Apply layout heuristics or use PP-Structure for grouping into tables

WRITTEN BY Shantanu Singh
Shantanu Singh is a Research Associate at CloudThat with expertise in Data Analytics and Generative AI applications. Driven by a passion for technology, he has chosen data science as his career path and is committed to continuous learning. Shantanu enjoys exploring emerging technologies to enhance both his technical knowledge and interpersonal skills. His dedication to work, eagerness to embrace new advancements, and love for innovation make him a valuable asset to any team.











Comments