

 Login
Login

 October 29, 2025
October 29, 2025|
Voiced by Amazon Polly |
Introduction
Building AI agents that can truly understand and evolve with users goes beyond capturing short conversations. While the short-term memory in Amazon Bedrock AgentCore helps maintain context within a single interaction, the real power lies in enabling agents to retain and learn from experiences over time. This is where long-term memory comes into play, transforming one-off exchanges into meaningful, ongoing relationships between users and AI systems.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
The challenges of persistent memory
When people engage, we do more than simply recall specific exchanges; we also derive meaning, identify trends, and gradually develop a deeper comprehension. To teach AI agents to react similarly, several difficult problems must be resolved:
- To decide which utterances should be processed temporarily vs stored for a long time, agent memory systems must be able to discriminate between ordinary chatter and insightful observations. “I’m a vegetarian” should stick in your memory, but “hmm, let me think” shouldn’t.
- Memory systems must be able to identify related data across time and combine it without producing inconsistencies or duplicates when a user states in January that they have a shellfish allergy and in March that they “can’t eat shrimp,” these statements should be interpreted as relevant facts and combined with preexisting knowledge without producing inconsistencies or repetitions.
- It is necessary to analyze memories in the context of their time. It takes careful management to ensure that the most recent desire is followed while preserving historical context when dealing with preferences that vary over time (for instance, the user enjoyed spicy chicken at a restaurant last year but now prefers moderate tastes).
- Finding pertinent memories rapidly becomes a significant challenge when memory storage expands to include hundreds or millions of data points. The system must strike a balance between effective retrieval and thorough memory retention.
How AgentCore long-term memory works?
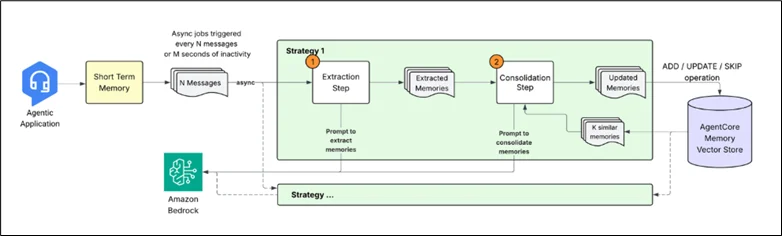
- Memory extraction: From conversation to insights:
An asynchronous extraction algorithm examines the conversational material to find important information when new occurrences are recorded in short-term memory. Large language models (LLMs) are utilized in this procedure to comprehend the context and extract pertinent information that needs to be stored in long-term memory. To create memory entries in a predetermined format, the extraction engine analyses incoming messages along with previous context. You can set up one or more memory strategies as a developer to only extract the kinds of data that are pertinent to your application’s requirements. The extraction process supports three built-in memory techniques:
- Semantic memory: Extracts facts and knowledge. Example:
|
1 |
"The customer's company has 500 employees across Seattle, Austin, and Boston" |
- User preferences: Captures both explicit and implicit preferences based on the given context. Example:
|
1 |
{“preference”: "Prefers Python for development work", “categories”: [“programming”, ”code-style”], “context”: “User wants to write a student enrollment website”} |
- Summary memory: Maintains the most important information in an organized XML format while generating ongoing narratives of discussions under various subjects scoped to sessions. For instance:
|
1 |
<topic=“Material-UI TextareaAutosize inputRef Warning Fix Implementation”> A developer successfully implemented a fix for the issue in Material-UI where the TextareaAutosize component gives a "Does not recognize the 'inputRef' prop" warning when provided to OutlinedInput through the 'inputComponent' prop. </topic> |
The system utilizes timestamps to process events for each approach, resolving conflicts and preserving context continuity. A single event can yield several memories, and since each memory technique functions separately, parallel processing is possible.
2. Memory consolidation:
The system utilizes intelligent consolidation to combine similar data, resolve disputes, and eliminate redundancies, rather than merely appending new data to existing storage. As new information becomes available, this consolidation ensures that the agent’s memory stays current and coherent.
- Retrieval: The system pulls the most semantically similar preexisting memories from the same namespace and approach for every newly retrieved memory.
- Intelligent processing: The LLM receives a consolidation prompt along with the newly created and recovered memories. Since “loves pizza” and “likes pizza” are essentially the same, the prompt avoids unnecessary updates by maintaining the semantic context. The prompt is made to manage a variety of situations while adhering to these fundamental ideas:
|
1 2 3 4 5 6 7 8 9 |
You are an expert in managing data. Your job is to manage memory store. Whenever a new input is given, your job is to decide which operation to perform. Here is the new input text. TEXT: {query} Here is the relevant and existing memories MEMORY: {memory} You can call multiple tools to manage the memory stores... |
The LLM chooses the proper course of action in response to this prompt:
- ADD: When fresh data differs from preexisting memories
- UPDATED: When fresh information updates or enhances preexisting memories, it can improve them.
- NO-OP: When the data is unnecessary
- Updates to the vector store: By designating the old memories as INVALID rather than immediately erasing them, the system maintains an unchangeable audit trail while implementing the decided actions.
This method ensures that similar memories are properly merged, duplication is kept to a minimum, and contradicting information is resolved (prioritizing recent information).
Advanced custom memory strategy Performance characteristics
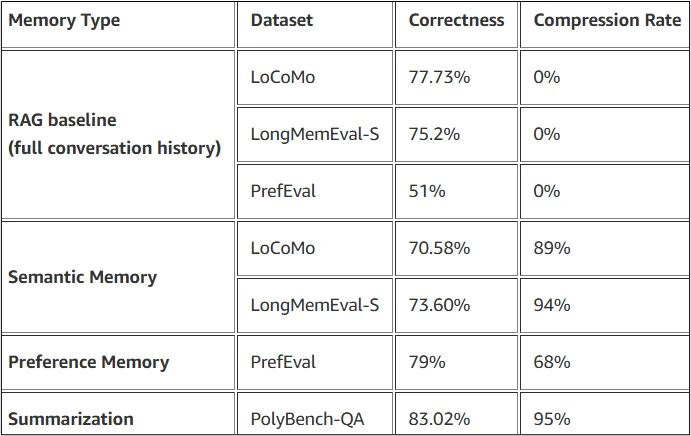
To examine various facets of long-term conversational memory, we tested our built-in memory technique on three publicly available benchmarking datasets:
- LoCoMo: Conversations that span several sessions and are produced by a machine-human pipeline using temporal event graphs and persona-based interactions. Evaluates long-term memory skills in a variety of realistic conversational contexts.
- LongMemEval: Assesses memory recall over lengthy discussions over several sessions and extended periods of time. 200 QA pairings were chosen at random to test assessment efficiency.
- PrefEval: Assesses the system’s capacity to retain and reliably apply user preferences over time by testing preference memory across 20 themes using 21-session instances.
- 807 Question Answer (QA) pairs from 80 trajectories were gathered from a coding agent doing tasks in PolyBench to create the PolyBench-QA dataset.
Conclusion
The Amazon Bedrock AgentCore Memory long-term memory system represents a significant advancement in creating AI agents that can evolve meaningfully alongside users. Through a combination of advanced information extraction, intelligent consolidation, and durable memory management, AgentCore enables agents to transform isolated interactions into cumulative knowledge. This approach ensures that AI systems not only recall past exchanges but also interpret them contextually, adapting their behavior, refining responses, and personalizing experiences over time.
Drop a query if you have any questions regarding Amazon Bedrock AgentCore and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What’s the difference between short-term and long-term memory in AgentCore?
ANS: – Short-term memory handles context within a single chat, while long-term memory stores key insights and preferences across sessions for personalized interactions.
2. How do LLMs help in Amazon Bedrock AgentCore’s long-term memory?
ANS: – LLMs extract, organize, and consolidate important details from conversations, ensuring memories stay accurate and meaningful.
3. How does Amazon Bedrock AgentCore manage large amounts of memory data?
ANS: – It uses vector storage, timestamps, and parallel processing to ensure fast, consistent, and scalable memory retrieval.

WRITTEN BY Aayushi Khandelwal
Aayushi is a data and AIoT professional at CloudThat, specializing in generative AI technologies. She is passionate about building intelligent, data-driven solutions powered by advanced AI models. With a strong foundation in machine learning, natural language processing, and cloud services, Aayushi focuses on developing scalable systems that deliver meaningful insights and automation. Her expertise includes working with tools like Amazon Bedrock, AWS Lambda, and various open-source AI frameworks.











Comments