

 Login
Login

 August 25, 2025
August 25, 2025|
Voiced by Amazon Polly |
Introduction
Today’s data-driven enterprises rely on processing and analyzing massive data sets. Cloud platforms like AWS have revolutionized storage and analytics for big data, but with this power comes the need for proper data management strategies. Data partitioning and file format selection are two foundational pillars for scalable, cost-effective big data analytics. Among the multitude of options, Parquet, ORC, and CSV are the most commonly encountered file formats when working with big data in AWS. Understanding their differences and how partitioning can accelerate queries and control costs is vital for every data engineer.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
The Importance of Data Partitioning
Data partitioning divides large datasets into smaller, more manageable subsets called partitions. Why bother? When dealing with terabytes (or petabytes) of data, scanning an entire table for every query is slow and expensive. Partitioning structures the data logically (e.g., by date, region, or other meaningful keys), enabling analytics engines to scan only relevant slices of your data.
Key Benefits of Partitioning
- Performance: Queries scan only relevant partitions, significantly reducing data read volume.
- Cost-efficiency: You pay for the data you scan on AWS services like Amazon Athena and Amazon Redshift Spectrum. Partitioning minimizes the scan footprint.
- Manageability: Data lifecycle management becomes easier, and you can delete or archive individual partitions as needed.
Common Partitioning Strategies:
- Temporal: Partition by year, month, day (e.g., year=2024/month=06/day=21)
- Categorical: Partition by region, customer ID, or product type
- Hybrid: Combine temporal and categorical for hierarchical partitioning
Example (S3 Data Lake Layout)
s3://example-bucket/events/year=2024/month=06/day=21/part-0001.snappy.parquet
File Format Deep Dive: Parquet, ORC, and CSV
- CSV: The Classic Workhorse
The comma-separated values (CSV) format is one of the simplest and most widely supported. It is human-readable and universally compatible. However, when it comes to the massive data and analytical workloads typical on AWS, CSV reveals key limitations:
- No compression: Large files take up significant storage.
- Lacks schema support: Data types and structure aren’t enforced.
- Slow for analytics: Queries must scan full files; no column skipping.
- No built-in support for splitting or parallel reads: This can slow down distributed computation.
When to use CSV:
Use CSV for small, ad-hoc data transfers or as an interchange format when readability/portability is critical.
- Parquet: The Columnar Powerhouse
Apache Parquet is an open-source, columnar file format. Unlike row-based formats (like CSV), Parquet organizes data by column. This design brings significant advantages for analytics:
- Efficient compression: Columnar repetition enables high compression ratios (Snappy, GZIP).
- Column pruning: Query engines (Amazon Athena, Amazon Redshift, Spark) read only necessary columns.
- Schema support and evolution: Parquet stores metadata for strict schema enforcement, supporting schema evolution.
- Parallel processing: Splitting and footer metadata enable efficient distributed reads.
AWS Support: All major analytics services (Amazon Athena, AWS Glue, Amazon EMR, Amazon Redshift Spectrum) have Parquet integration.
- ORC: Optimized for the Hadoop Ecosystem
Optimized Row Columnar (ORC) is another columnar format designed for big data. Originally built for the Hadoop ecosystem, ORC has many of the same strengths as Parquet:
- Advanced compression and encoding: Predicate pushdown, light metadata storage, and the ability to skip non-relevant data.
- Schema evolution: Similar to Parquet.
- Efficient analytics: Superb for storing large, read-heavy data where analytical queries dominate.
AWS Support: Supported by Amazon Athena, AWS Glue, Amazon EMR, and Amazon Redshift.
Comparison Table
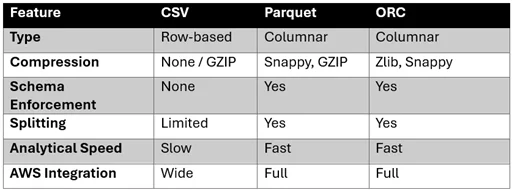
Why Parquet and ORC Outperform CSV on AWS
If you’re building analytics or machine learning pipelines on AWS, Parquet or ORC must be your go-to due to:
- Lower storage costs (thanks to compression)
- Faster query times (especially for columnar scans)
- Native partitioning integrations in AWS Glue/Athena
- Compatibility with downstream data science tools
CSV, in contrast, will:
- Inflate storage bills rapidly at scale
- Slow down queries due to a lack of skip/scan efficiency
- Causes more errors due to a lack of schema enforcement
Best Practices: Combining Partitioning and Columnar Formats
- Partition First: Decide on business-relevant partition keys, date, and region, which are common in event or sales data.
- Store as Parquet or ORC: Convert incoming data to columnar formats.
- Register with AWS Glue Catalog: Maintain metadata and optimize for query engines (Amazon Athena, Spark, Amazon Redshift).
- Tune partitions: Avoid too many small partitions (leads to “small files problem”), but don’t go too coarse (slows down queries).
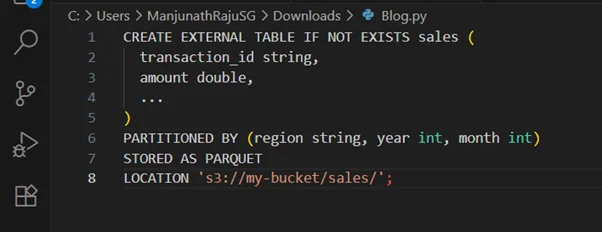
Example Table Declaration (Amazon Athena):
Conclusion
For any growing data pipeline, revisiting these foundation choices is critical for scalable, cost-effective analytics.
Drop a query if you have any questions regarding Big Data processing and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Why is data partitioning important when working with big data on AWS?
ANS: – Partitioning reduces the amount of data scanned during queries, significantly speeding up analysis and lowering costs on services like Amazon Athena and AWS Glue.
2. What major advantages do Parquet and ORC offer over CSV?
ANS: – Parquet and ORC are columnar formats that enable compression, faster queries via predicate pushdown, and efficient column pruning. At the same time, CSV offers none of these benefits and is best suited for small-scale jobs or portability.
3. How can I convert existing CSV data to Parquet or ORC on AWS?
ANS: – Yes, AWS services like Amazon Athena and AWS Glue allow you to convert CSV data into Parquet or ORC using SQL queries (e.g., CREATE TABLE AS SELECT) or ETL jobs, unlocking performance improvements.

WRITTEN BY Manjunath Raju S G
Manjunath Raju S G works as a Research Associate at CloudThat. He is passionate about exploring advanced technologies and emerging cloud services, with a strong focus on data analytics, machine learning, and cloud computing. In his free time, Manjunath enjoys learning new languages to expand his skill set and stays updated with the latest tech trends and innovations.











Comments